腾讯音乐娱乐推出开源虚拟人视频生成框架MusePose腾讯音乐娱乐旗下天琴实验室推出开源虚拟人视频生成框架MusePose,MusePose 是 Muse 开源系列的最后一个组件,与 MuseV 和 MuseTalk 一起,标志着向构建端到端虚拟人物生成...新技术# MusePose# 虚拟人2年前09960
StableAvatar:首个端到端生成无限长度虚拟人视频的扩散模型你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation...视频模型# StableAvatar# 虚拟人8个月前05290
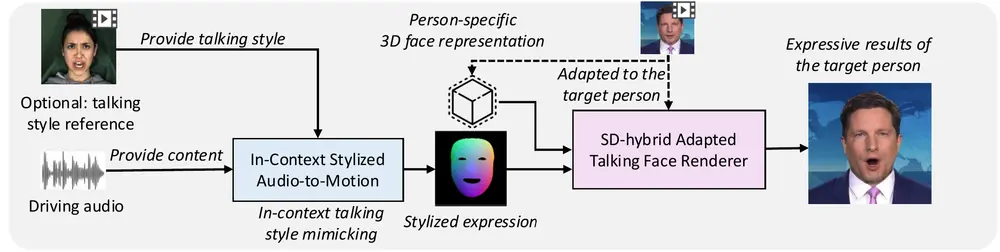
MimicTalk:用于实现特定说话人的高表现力的虚拟人视频合成说话人脸生成(Talking Face Generation, TFG)的目标是将目标身份的脸部动画化,以创建逼真的说话视频。个性化TFG是这一任务的一个重要变体,强调生成的视频在静态外观和动态说话风...新技术# MimicTalk# 虚拟人1年前05060
浙大 × 阿里巴巴推出 OmniAvatar:首个支持音频驱动全身动画的可控虚拟人视频生成模型在数字人、虚拟主播、AI 视频创作等领域,仅靠语音生成逼真且动作自然的虚拟形象视频,一直是生成式 AI 的关键挑战之一。 现有音频驱动视频生成方法大多聚焦于面部动画,尤其是唇部同步,而对身体动作、姿态...视频模型# OmniAvatar# 虚拟人8个月前02500