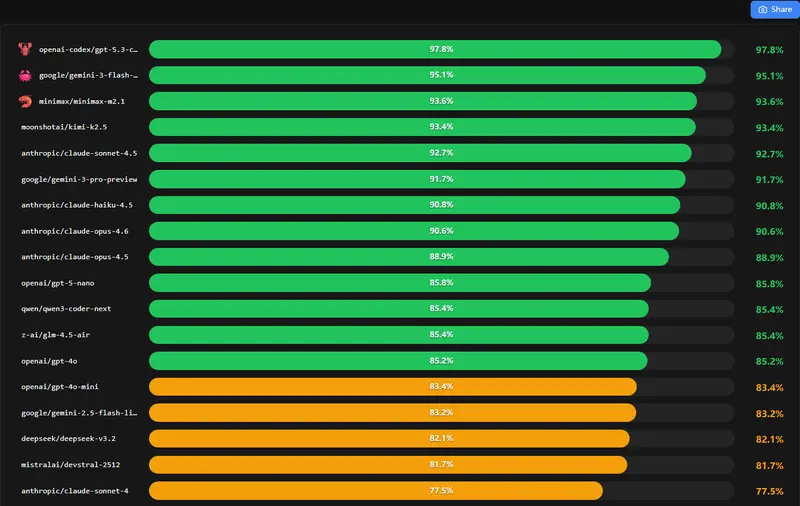
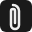PinchBench 是一个专为 OpenClaw 生态设计的基准测试系统,通过 23 项真实世界任务,全方位评估大语言模型作为“编码智能体”的实际能力。它不再依赖静态的选择题或简单的代码补全,而是让模型在模拟的真实工作流中,完成从日历管理、股市研究到复杂 API 编排的全套动作。

对于开发者而言,PinchBench 是一张清晰的“选型地图”:它通过量化成功率、执行速度和运行成本,帮助你在众多模型中找到最适合你业务场景的那一个。
核心机制:如何构建一个“真实”的考题?
PinchBench 的任务定义摒弃了黑盒,采用透明、可审计的 YAML + Markdown 格式,存储在 pinchbench/skill 仓库中。每个任务都是一个完整的微型项目,包含五大要素:
- 🗣️ 真实提示 (Prompt):直接复刻真实用户的自然语言请求,拒绝人工修饰的“完美题目”。
- 🎯 预期行为:详细描述智能体应采取的方法论和关键决策点,界定“聪明”的标准。
- ✅ 原子化评分标准:将成功拆解为一个个可验证的检查项(Checklist),杜绝模糊打分。
- 🤖 自动检查脚本:基于 Python 函数,直接扫描工作区文件系统和执行日志,客观判定结果。
- 🧐 LLM 评判准则:针对定性任务(如写作、摘要),为裁判模型(如 Claude Opus)提供详细的评分指南,确保主观题也有客观标尺。
🏆 23 项实战任务全景图
PinchBench 覆盖了从基础交互到复杂工作流的六大类别,共 23 项 精心设计的任务:
1. 🛠️ 基础能力与健全性
- ✅ 健全性检查:确认智能体能正常启动并响应问候。
- 🧠 上下文记忆检索:从笔记文件中精准提取事实,考验 RAG 能力。
- 📁 文件结构创建:一键生成标准项目目录(源码、README、.gitignore),考察工程规范。
2. 📅 个人助理与生活自动化
- 📅 日历事件创建:解析自然语言,生成准确的 ICS 文件(时间、人物、描述)。
- 🌤️ 天气脚本创建:编写 Python 脚本调用 API,含错误处理,考察代码生成与调试。
- ✉️ 专业邮件起草:高情商拒绝会议邀请,考验语气把控与社交智慧。
3. 📊 信息检索与数据分析
- 📈 股价研究:联网查询实时股价,生成格式化报告。
- 🎤 技术会议研究:汇编 5 个真实会议的详细信息(名称、日期、地点、URL)。
- 📄 文档摘要:阅读长文档,输出精准的 3 段式摘要。
- 📑 CSV/Excel 摘要:分析数据文件,提取洞察并生成报告。
- 🏢 竞争性市场研究:深度调研 APM 领域格局,识别关键玩家。
4. 🔌 OpenClaw 生态专属技能
- 🔌 安装 ClawdHub 技能:从注册表安装技能并验证,考察工具链熟悉度。
- 🔍 搜索并安装技能:根据需求(如“天气”)搜索并安装最佳技能,考验语义匹配。
- 🔄 多步骤 API 工作流:读取配置 -> 提取 API Key -> 编写脚本 -> 记录日志,全链路自动化。
5. 🎨 内容创作与优化
- ✍️ 博客文章撰写:结构化写作,论点清晰,含实例。
- 🤖 AI 内容人性化:将机械的 AI 文本改写为自然的人话,考验风格迁移。
- 📬 每日研究摘要:综合多份文档,生成连贯的日报。
- 👶 面向儿童的 PDF 摘要:用“费曼技巧”将技术文档解释给 5 岁孩子听。
6. 🧠 高级认知与记忆
- 📖 OpenClaw 报告理解:从研究报告中提取特定信息回答问题。
- 💾 第二大脑知识持久化:跨会话存储与回忆信息,考验长期记忆机制。
- 🎨 AI 图像生成:根据描述生成图像并保存,考察多模态工具调用。
- 📬 邮件分类与搜索:对收件箱进行紧急度排序及定向搜索摘要。
三维评分体系:客观、主观与混合
PinchBench 采用灵活的评分策略,确保每种任务都能得到最公正的评价:
| 评分类型 | 机制 | 适用场景 |
|---|
| 🤖 自动评分 (Auto) | Python 脚本检查工作区文件状态、日志记录及返回值。 | 代码生成、文件操作、数据提取等确定性任务。 |
| 🧐 LLM 评判 (LLM-Judge) | 由 Claude Opus 等强力模型依据详细准则进行定性评估。 | 写作质量、语气把握、摘要准确性等创造性任务。 |
| 🔀 混合评分 (Hybrid) | 自动检查验证硬性指标(如文件存在),LLM 评估软性指标(如内容质量)。 | 复杂工作流、多模态任务、综合分析报告。 |
🔄 版本控制:可审计、可比较的“科学实验”
PinchBench 引入了严格的Git 哈希版本控制机制,确保每一个分数都可追溯:
- 唯一标识:每个基准测试版本由
pinchbench/skill 仓库的 Git Commit Hash 唯一标识。 - “当前”版本逻辑:
- 非实质性更新(如文档、CI 配置修改):新版本仍标记为 "Current",分数可与旧版直接对比,排行榜合并显示。
- 实质性更新(如修改提示词、评分逻辑):开启新一代 (Generation),旧版本归档,新旧分数分开统计,避免不公平对比。
- 历史永存:所有历史版本及其结果永久保留,用户可随时通过版本选择器回溯查看,重现当时的评测环境。
💡 为什么开发者需要 PinchBench?
在 OpenClaw 生态中,模型选择不再是“拍脑袋”:
- 拒绝参数迷信:参数量大不代表代理能力强。PinchBench 揭示哪些模型真正擅长工具调用和多步规划。
- 成本效益分析:不仅看成功率,还看速度和Token 消耗。也许一个较小的模型在特定任务上性价比更高。
- 场景化选型:如果你的应用侧重“文档处理”,就参考相关子集分数;如果侧重“代码生成”,则关注编程类任务表现。
PinchBench 不仅仅是一个排行榜,它是 OpenClaw 智能体进化的“指挥棒”。