
Head AI
Head AI 是“全球首个人工智能营销助手”,不仅仅是一个工具,而是一个先进的 AI 助手,旨在通过预测、执行和优化营销策略,消除营销中的猜测,帮助企业实现增长。
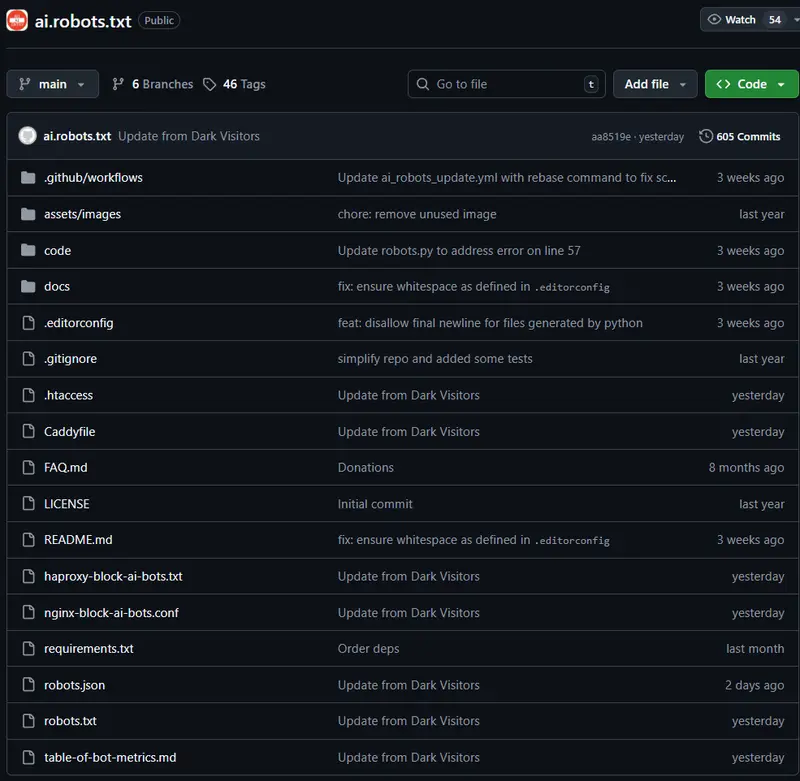
ai.robots.txt收集了目前市面上所有已知的 AI 相关网络爬虫(User-Agent),无论它们来自 OpenAI、Google、Amazon 还是其他新兴平台。你可以直接使用项目提供的配置文件,轻松在自己的 Web 服务器上阻止这些爬虫访问。
如果你不希望自己的网站内容被 AI 模型爬取用于训练,现在有一个简单、统一且持续维护的开源方案:ai.robots.txt。
这个项目收集了目前市面上所有已知的 AI 相关网络爬虫(User-Agent),无论它们来自 OpenAI、Google、Amazon 还是其他新兴平台。你可以直接使用项目提供的配置文件,轻松在自己的 Web 服务器上阻止这些爬虫访问。
ai.robots.txt 仓库提供了多种格式的配置文件,适配主流 Web 服务器和代理工具:
robots.txt:遵循标准的“机器人排除协议”(Robots Exclusion Protocol),适用于所有支持该协议的爬虫。.htaccess:用于 Apache 服务器,可在匹配到 AI 爬虫 User-Agent 时返回 403 或自定义错误页面(注意:官方文档建议优先使用主配置而非 .htaccess 以提升性能)。nginx-block-ai-bots.conf:Nginx 配置片段,通过 include 指令嵌入到任意 server 块中即可生效。Caddyfile:提供一组正则匹配的 Header 规则,配合 abort @aibots 可立即中止请求。haproxy-block-ai-bots.txt:用于 HAProxy 的 User-Agent 黑名单,通过 ACL 规则实现拦截:
acl ai_robot hdr_sub(user-agent) -i -f /etc/haproxy/haproxy-block-ai-bots.txt
http-request deny if ai_robot
注意:文件路径需根据你的实际部署环境调整。
微软 Bing 的爬虫会将抓取内容用于 AI 模型训练。即使你已在 robots.txt 中限制,Bing 仍可能爬取。此时,建议在网页 <head> 中添加如下 meta 标签显式退出:
<meta name="bingbot" content="noai">
项目中的许多爬虫识别规则最初来自 Dark Visitors 项目,感谢其对 AI 爬虫行为的持续追踪。ai.robots.txt 在此基础上进一步标准化、自动化,并开放贡献。
如果你发现新的 AI 爬虫未被收录,欢迎提交 Pull Request:
robots.txt 和 ai.txttable-of-bot-metrics.md 中补充其用途、所属公司等背景信息,帮助其他用户判断是否应阻止所有新增内容应先写入
robots.json。项目通过 GitHub Action 自动同步生成其余配置文件和文档。
项目使用 Python 编写验证脚本。如需本地测试变更,请执行:
pip install -r requirements.txt
python code/tests.py
仓库还包含 .editorconfig,确保贡献者使用一致的代码风格。
https://github.com/ai-robots.txt/ai.robots.txt/releases.atom目前已有社区开发的 Traefik 中间件插件,可动态注入 robots.txt 规则。你也可以选择手动配置 Traefik,通过静态文件服务方式统一提供 robots.txt。
如果你不打算完全禁止 AI 爬取,而是希望以授权方式允许使用,并保留集体谈判权利,可以考虑 RSL(Really Simple Licensing) 标准。项目提到,目前已有一个 WordPress 插件实现了 RSL 协议及配套的支付处理功能,适合内容创作者使用。













