
Captions
Captions利用先进的人工智能技术,让任何人都能通过几次简单的点击,使用手机制作出录音室品质的视频。无论是脚本编写、录制、编辑还是分享,Captions都能无缝支持您的每一个创作环节。
英伟达正式宣布将 Audio2Face(A2F)全面开源,向所有开发者免费开放这一基于音频生成 3D 面部动画的 AI 工具。此举意味着游戏开发者、内容创作者和独立工作室现在可以无需许可限制地使用该技术,为虚拟角色实现高质量的唇形同步与表情动画。
Audio2Face 曾是英伟达Omniverse 平台中仅供企业用户使用的高级功能之一,如今随着模型、SDK 和训练框架的完整释放,它已成为一个真正开放的 AI 动画工具链。
Audio2Face 是一款利用AI从音频输入自动生成 3D 角色面部动画的技术。只需一段语音,系统即可分析其声学特征——如音调、节奏、重音和情感倾向——并据此驱动虚拟头像完成包括嘴唇、脸颊、眼睛、眉毛乃至舌头在内的精细面部运动。
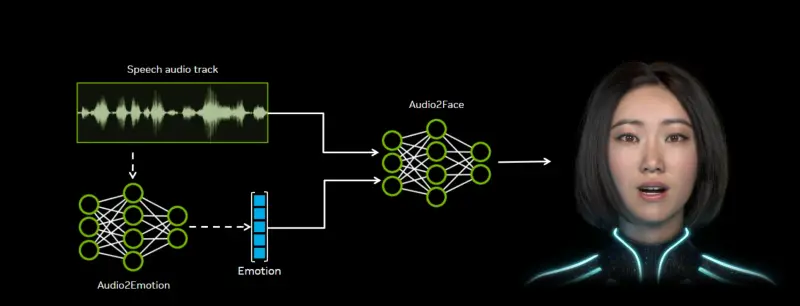
其输出可用于预渲染内容或实时场景,广泛适用于:
英伟达强调,该工具不仅支持预先录制的内容,还可通过 LiveLink 实现与 Unity、Unreal Engine 等引擎的实时数据流对接,将混合形状权重(blend shapes)直接传输到外部应用程序。
此次开源并非仅发布成品软件,而是包含以下全部组件:
这意味着开发者不仅可以“开箱即用”,还能根据特定语言、口音或艺术风格调整模型行为,提升动画在不同文化语境下的自然度。
此外,系统支持运行时调用或纳入传统内容生产流程,并可导出多种格式的 blend shape 权重,兼容主流建模与动画软件。
一些游戏开发团队已率先采用 Audio2Face 技术:
这些案例表明,该技术不仅能处理人类语音,也可扩展至非现实角色的声音驱动场景。
要运行 Audio2Face,需满足以下基本条件:
对于头部网格建模,A2F 要求:
Audio2Face 的开源填补了当前 AI 驱动动画领域的一个关键空白:大多数现有方案要么精度不足,要么依赖昂贵的动作捕捉设备。而英伟达提供的是一个经过工业验证、高保真且完全可编程的解决方案。
尤其对于中小型团队而言,这项技术大幅降低了创建逼真角色动画的时间成本与技术门槛。结合其对实时流和跨引擎支持的能力,未来有望成为虚拟角色开发的标准工具之一。













