
Vidu
Vidu 是一款由生数科技与清华大学合作开发的 AI 视频生成工具,2024 年推出,专注于从文本和图像生成高清视频。它支持文本转视频、图像转视频和参考转视频模式,适合社交媒体、广告和电影制作。
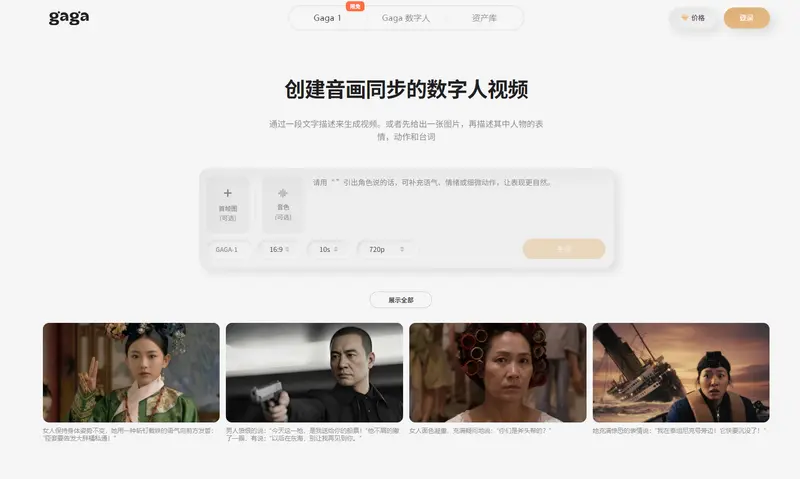
提到 AI 视频生成,你是否还停留在“口型对不上、表情僵硬、满是塑料感”的印象中?传统工具往往需要分别处理文本转语音、唇同步、面部动画,最终产出的内容拼凑感强,容易陷入“恐怖谷”效应,难以满足影视级、商业化的创作需求。
而 Gaga AI 推出的 GAGA-1 模型,正彻底颠覆这一现状——它不是一款简单的视频生成工具,而是首个“整体式 AI 演员”。从声音、表情到肢体微动作,所有元素都在生成时实时统一,最终呈现出“声、形、戏,浑然一体”的影视级表演,让 AI 视频真正告别“机械感”。

只需一张图片或一段音频,GAGA-1 就能快速生成口型精准、表情自然、情感丰沛的数字人视频,无需专业拍摄设备,无需复杂后期剪辑,一键即可让创意落地。
传统 AI 视频生成的核心问题,在于“碎片化工作流”——语音、唇动、表情是分开生成后拼接的,自然会出现同步错位、情感脱节。而 GAGA-1 的创新,在于其“整体式生成架构”,完全模拟人类演员的表演逻辑:说话时,声音、表情、微动作本就是不可分割的整体,而非刻意配合。
这种设计带来了四大核心优势,让数字表演更逼真、更有感染力:
简单说,GAGA-1 不只是“生成视频”,而是“生成一场完整的表演”。
此前,内容创作者使用 AI 视频工具时,往往要面对诸多妥协:
而 GAGA-1 凭借“整体式生成”的核心逻辑,从根源上解决了这些问题:
GAGA-1 的“整体式 AI 演员”定位,让它在多个行业都具备强大的实用性,彻底释放创意生产力:













