AI Speaker
AI Speaker 是一款基于微软 TTS 服务的在线文字转语音(TTS)工具,能够将文字即时转换为自然流畅的 语音,支持100多种语言和600多种AI语音。
WhisperLiveKit 提供了一种轻量、可扩展的解决方案——它将实时语音转文本与说话者分割能力集成于本地运行环境中,无需依赖云端服务,兼顾性能与数据安全。
在需要语音识别的场景中,隐私、延迟与部署灵活性往往是关键考量。WhisperLiveKit 提供了一种轻量、可扩展的解决方案——它将实时语音转文本与说话者分割能力集成于本地运行环境中,无需依赖云端服务,兼顾性能与数据安全。
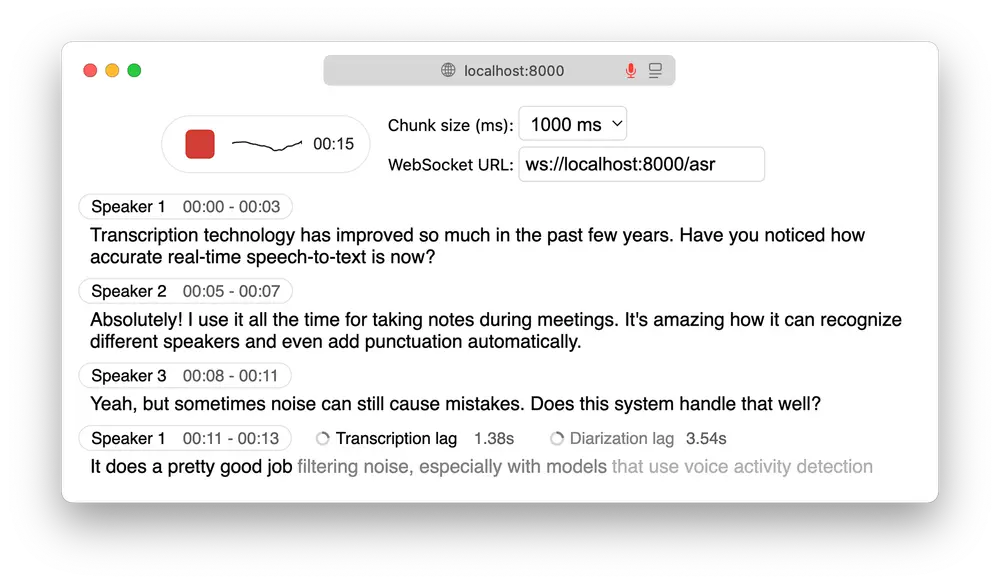
该项目基于 OpenAI 的 Whisper 模型生态构建,结合 FastAPI 后端与简洁的 Web 前端,支持浏览器端直接使用,适用于会议记录、访谈整理、多角色对话分析等多种实际场景。
WhisperLiveKit 不仅实现基础的语音识别,更在本地环境中集成了多项进阶功能:
WhisperLiveKit 依赖 FFmpeg 进行音频编解码处理,必须提前安装。
| 操作系统 | 安装命令 |
|---|---|
| Ubuntu/Debian | sudo apt install ffmpeg |
| macOS | brew install ffmpeg |
| Windows | 从 https://ffmpeg.org/download.html 下载可执行文件,并将其路径加入系统环境变量 PATH |
提示:可通过命令
ffmpeg -version验证是否安装成功。
安装 Python 包:
pip install whisperlivekit
启动服务:
whisperlivekit-server --model tiny.en
打开浏览器访问:http://localhost:8000
即可开始语音输入,实时查看转录结果。
若需支持 HTTPS(例如在局域网内通过 IP 访问),可在启动时添加
--ssl-key和--ssl-cert参数配置证书文件。
WhisperLiveKit 支持多种后端与增强功能,通过可选依赖灵活配置:
| 功能 | 安装命令 |
|---|---|
| 说话者分割 | pip install whisperlivekit[diarization] |
| 原始 Whisper 后端 | pip install whisperlivekit[whisper] |
| 改进时间戳支持 | pip install whisperlivekit[whisper-timestamped] |
| Apple Silicon 优化支持 | pip install whisperlivekit[mlx-whisper] |
| OpenAI API 调用支持 | pip install whisperlivekit[openai] |
若启用说话者分割功能,需下载以下 Hugging Face 模型并接受其使用条款:
pyannote/segmentationpyannote/segmentation-3.0pyannote/embedding登录 Hugging Face 账户以获取访问权限:
huggingface-cli login
登录后,系统将自动拉取所需模型。
tiny.en),可在资源受限设备上运行。