海螺语音
MiniMax旗下的海螺AI上线了基于T2A-01系列语音模型的“海螺语音”。这一更新为用户带来了更加自然、流畅的超拟人人声体验。
NovaSR 是一个仅 50KB 的音频上采样模型,能够将模糊的 16kHz 音频升级为清晰明快的 48kHz 音频,处理速度超过实时速度的 3500 倍。
一个仅 52KB 大小的音频超分辨率模型,能将模糊的 16kHz 音频高质量升频至 48kHz,处理速度高达 3600 倍实时——这并非理论宣传,而是开源项目 NovaSR 的实际表现。
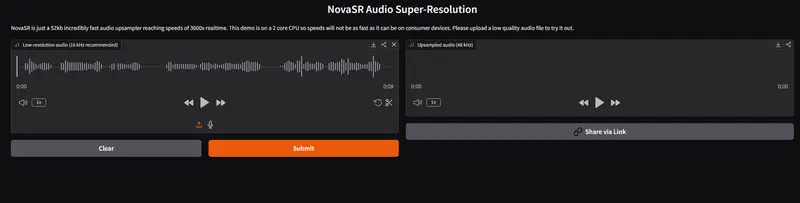
在当前主流音频增强模型动辄占用数百 MB 甚至数 GB 显存的背景下,NovaSR 以极小的体积、极快的速度和出人意料的音质,重新定义了“效率优先”的音频处理可能性。
NovaSR 的核心优势可概括为三点:
作为对比,主流音频超分模型如 AudioSR(约 2GB)、FlashSR(1GB)和 FlowHigh(450MB)不仅体积庞大,实时性能也远逊于 NovaSR:
| 模型 | 实时倍数 | 模型大小 |
|---|---|---|
| NovaSR | 3600× | ~52 KB |
| FlowHigh | 20× | ~450 MB |
| FlashSR | 14× | ~1000 MB |
| AudioSR | 0.6× | ~2000 MB |
这意味着,NovaSR 不仅能在服务器端批量处理音频,更具备在手机、嵌入式设备或浏览器中运行的潜力。
NovaSR 已开源,安装仅需一行命令:
pip install git+https://github.com/ysharma3501/NovaSR.git
加载与推理同样简洁:
from NovaSR import FastSR
# 自动从 Hugging Face 下载模型
upsampler = FastSR()
# 加载音频文件(支持 WAV、MP3 等)
lowres_audio = upsampler.load_audio('audio_path.wav')
# 执行升频
highres_audio = upsampler.infer(lowres_audio).cpu()
# 播放结果(48kHz)
from IPython.display import Audio
Audio(highres_audio, rate=48000)
若在 CPU 上运行,建议关闭半精度以获得 3–4 倍加速:
upsampler = FastSR(half=False)
NovaSR 为何能如此小巧?其架构仅包含 不到 10 层微型 Conv1D,并采用源自 BigVGAN 的 Snake 激活函数,在参数量极度受限的情况下,仍保留了对高频细节的有效建模能力。
训练数据方面,仅使用了 100 小时 的公开语音数据(MLS-SIDON 与 VCTK),未依赖大规模私有语料,进一步验证了其设计效率。
作者表示,完整的客观指标(如 PESQ、STOI)和主观听感基准测试正在准备中,后续将公开详细评估结果。