
GPT-Realtime
gpt-realtime 的发布,不仅是技术迭代,更意味着 OpenAI 的语音能力已具备**企业级稳定性与功能性**。它不再只是一个演示功能,而是可以嵌入真实业务流程的工具。对于开发者而言,Realtime API 的全面开放,加上 SIP、MCP、图像输入等企业级功能的加入,意味着构建复杂语音应用的门槛正在降低。
将一本小说转化为一部由不同角色配音、带有自然停顿和情感表达的有声书,通常需要一个专业的配音团队。现在,借助 Alexandria,你可以在本地完成这一切。它是一个基于 Qwen3-TTS 引擎构建的开源工具,利用大语言模型(LLM)自动标注脚本,并为每个角色分配独特的声音,最终导出为可直接使用的 MP3 或供专业编辑的 Audacity ...
无需专业配音团队,无需复杂音频编辑技巧——Alexandria 借助 AI 驱动的脚本标注与文本转语音技术,能将任意书籍、小说文本转化为带多角色配音的完整有声书。内置 Qwen3-TTS 引擎,支持本地/云端运行,搭配浏览器可视化编辑器,可逐行微调语音风格,最终导出 MP3 或适配 Audacity 的多轨编辑文件,全程自动化且高度可定制。
作为基于 Qwen3-TTS 构建的专业有声书生成工具,Alexandria 核心优势在于:通过大语言模型(LLM)自动标注脚本,为每个角色分配专属声音;支持按文本描述定制声音风格、克隆参考音频音色,甚至通过 LoRA 微调训练专属声音;批量处理效率可达实时速度的 3-6 倍,兼顾制作效率与音频质量。
Alexandria 依托 LLM 完成脚本的自动化解析与优化,从源头上保证有声书的叙事逻辑:
内置 Qwen3-TTS 引擎,无需依赖外部服务器,语音生成能力覆盖多语言、多风格、多定制方式:
8 标签页模块化界面,覆盖从配置到导出的全流程,新手也能快速上手:
使用前需确保环境满足以下条件,保证工具稳定运行:
| 类别 | 具体要求 | 补充说明 |
|---|---|---|
| 基础工具 | Pinokio | 必须安装,作为运行载体 |
| LLM 服务器 | LM Studio/Ollama(本地)、OpenAI API(云端)等 | 推荐使用 Qwen3 模型,脚本生成效果最佳 |
| GPU | 最低 8GB 显存,推荐 16GB+ | 需支持 NVIDIA CUDA 11.8+ 或 AMD ROCm 6.0+;CPU 模式可用但速度极慢 |
| 内存 | 最低 8GB,推荐 16GB | 影响批量处理效率 |
| 磁盘 | 约 20GB 空间 | 含 8GB 虚拟环境/PyTorch、7GB 模型权重,及音频工作空间 |
⚠️ 重要提示:无需额外部署 TTS 服务器,Alexandria 内置 Qwen3-TTS 引擎,模型权重首次使用时自动下载(单变体约 3.5GB);更多进阶指南可参考项目 Wiki。
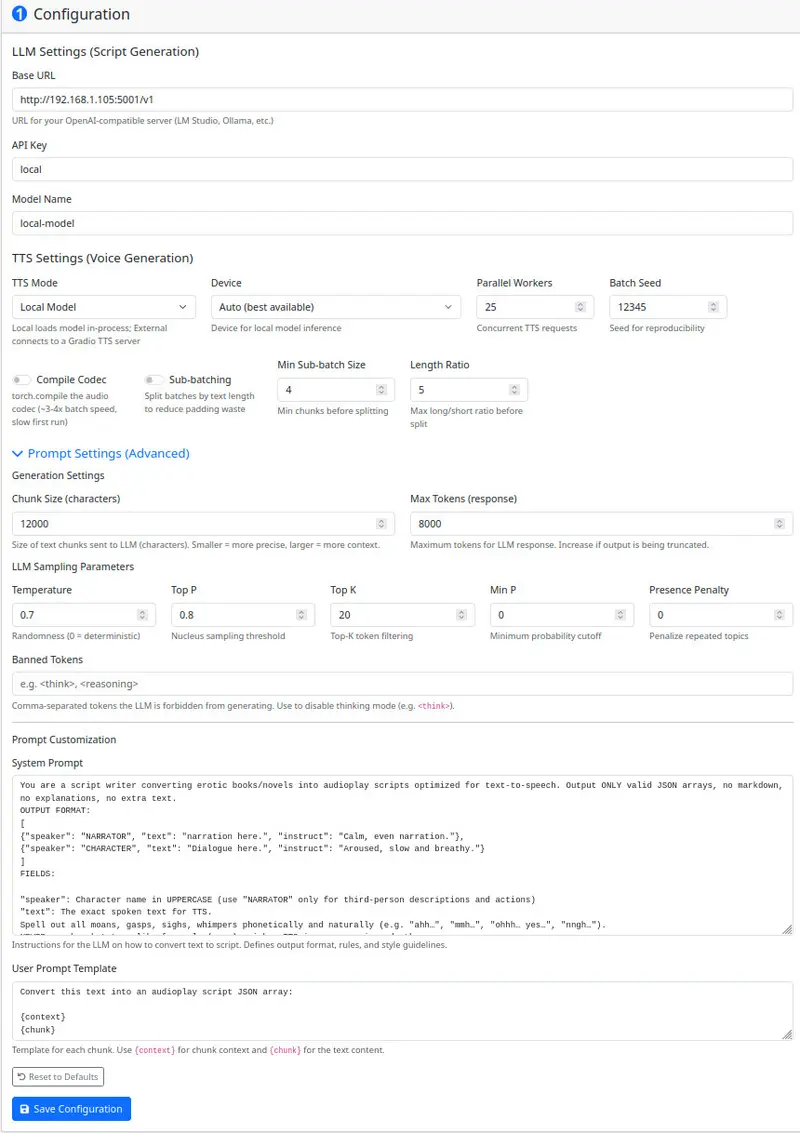
https://github.com/Finrandojin/alexandria-audiobook;核心配置 LLM 和 TTS 引擎,决定生成效率和效果:
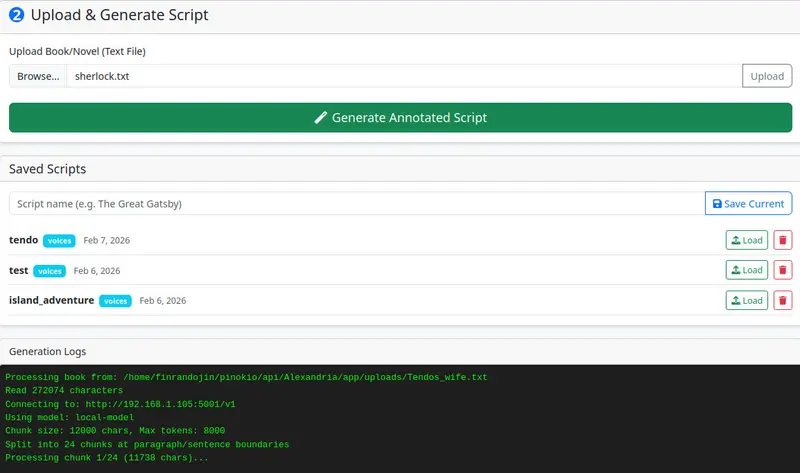
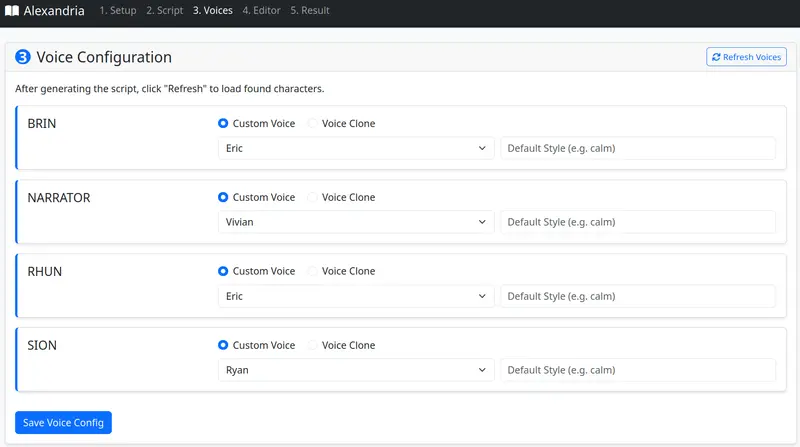
http://localhost:1234/v1,Ollama 填 http://localhost:11434/v1;local 即可,云端需填对应平台密钥;qwen2.5-14b;local(内置引擎,推荐),设备选 auto,语言按需选择。.txt/.md 格式的书籍文本,点击「生成标注脚本」;刷新声音列表后,为每个说话人配置音色:
按需下载合并后的 MP3,或导出 Audacity 多轨压缩包,完成制作。
除基础配置外,这些高级设置可提升生成效率:
torch.compile,批量解码速度提升 3-4 倍(首次生成需 30-60 秒预热);仅需文本描述即可生成专属声音:
若需长期复用某类音色,可训练 LoRA 适配器:
metadata.jsonl,或用「数据集构建器」交互式创建;| 模式 | 速度 | 特点 | 适用场景 |
|---|---|---|---|
| 标准模式 | ~1倍实时速度 | 按说话人种子生成,支持声音克隆 | 少量区块、需精准复刻音色 |
| 批量(快速) | 3-6倍实时速度 | 按文本长度分组,显存利用率高 | 整本书批量生成,追求效率 |
local;| 配置 | 吞吐量 | 54分钟音频生成耗时 |
|---|---|---|
| 标准模式 | ~1倍实时 | 约54分钟 |
| 批量模式(无编译) | ~2倍实时 | 约27分钟 |
| 批量模式(开启编译) | 3-6倍实时 | 约16分钟 |
使用 ROCm 环境的 AMD 显卡,工具会自动应用优化:
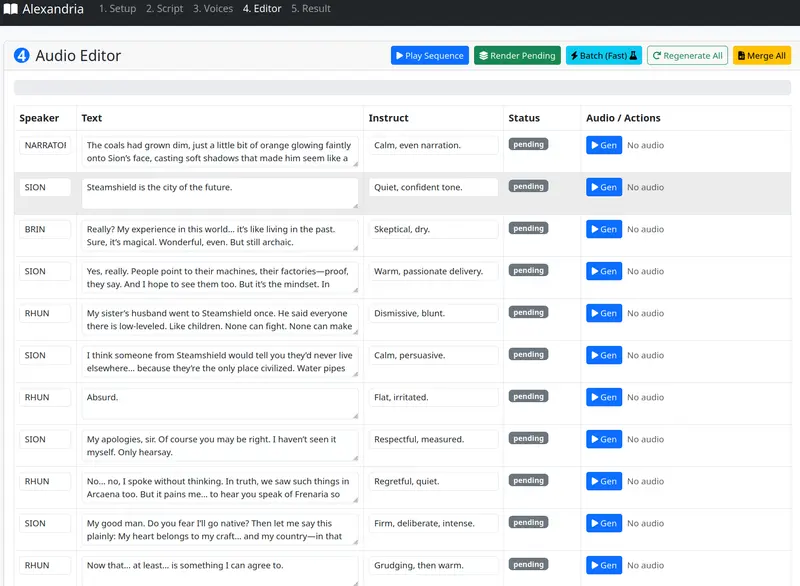
torch.compile 兼容性问题,无需手动配置。结构化存储角色、文本、指令,示例:
[
{"speaker": "NARRATOR", "text": "The door creaked open slowly.", "instruct": "Calm, even narration."},
{"speaker": "ELENA", "text": "Ah! Who's there?", "instruct": "Startled and fearful, sharp whispered question, voice cracking with panic."}
]
instruct 字段:2-3 句语音指令,直接控制 TTS 输出风格(如“悲痛欲绝,说话间抽泣,以啜泣声结束”);cloned_audiobook.mp3(含自然停顿,可直接播放);voicelines/ 目录下按说话人命名的 MP3,便于单句编辑;Alexandria 提供完整 REST API,支持 Python/JavaScript 集成,实现自动化制作:
import requests
import time
BASE = "http://127.0.0.1:4200"
# 上传文本文件
with open("mybook.txt", "rb") as f:
requests.post(f"{BASE}/api/upload", files={"file": f})
# 生成脚本并等待完成
requests.post(f"{BASE}/api/generate_script")
while True:
status = requests.get(f"{BASE}/api/status/script_generation").json()
if status.get("status") in ["completed", "error"]:
break
time.sleep(2)
# 配置声音并批量生成
voice_config = {"NARRATOR": {"type": "custom", "voice": "Ryan", "character_style": "calm"}}
requests.post(f"{BASE}/api/save_voice_config", json=voice_config)
chunks = requests.get(f"{BASE}/api/chunks").json()
requests.post(f"{BASE}/api/generate_batch_fast", json={"indices": [c["id"] for c in chunks]})
# 合并并下载
requests.post(f"{BASE}/api/merge")
with open("audiobook.mp3", "wb") as f:
f.write(requests.get(f"{BASE}/api/audiobook").content)
const BASE = "http://127.0.0.1:4200";
// 上传文件
const formData = new FormData();
formData.append("file", fileInput.files[0]);
await fetch(`${BASE}/api/upload`, { method: "POST", body: formData });
// 生成脚本并等待完成
await fetch(`${BASE}/api/generate_script`, { method: "POST" });
async function waitForTask(taskName) {
while (true) {
const res = await fetch(`${BASE}/api/status/${taskName}`);
const data = await res.json();
if (data.status === "completed" || data.status === "error") return data;
await new Promise(r => setTimeout(r, 2000));
}
}
await waitForTask("script_generation");
// 配置声音并生成
await fetch(`${BASE}/api/save_voice_config`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ NARRATOR: { type: "custom", voice: "Ryan" } })
});
// 下载有声书
await fetch(`${BASE}/api/merge`, { method: "POST" });
const audioRes = await fetch(`${BASE}/api/audiobook`);
const blob = await audioRes.blob();
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = "audiobook.mp3";
a.click();
脚本生成优先选择非思考型模型,效果更优:













