
Chrome DevTools MCP
chrome-devtools-mcp 让你的编码代理(如 Gemini、Claude、Cursor 或 Copilot)控制并检查实时 Chrome 浏览器。它充当 Model-Context-Protocol (MCP) 服务器,让你的 AI 编码助手访问 Chrome DevTools 的全部功能,用于可靠的自动化、深入调试和性能分析。
随着 AI 代理在企业中的广泛应用,如何准确评估其性能,已成为继“部署”之后的核心挑战。
Salesforce 研究团队近日推出 MCPEval——一个基于 模型上下文协议(Model Context Protocol, MCP) 架构的开源评估工具包,为 AI 代理提供自动化、可迭代、环境一致的性能测试方案。它不仅是一个评测框架,更是一个“即插即用”的代理质量保障系统。

当前,大多数 AI 代理评估依赖于静态、预定义的任务,例如让代理完成一组固定指令并判断“成功”或“失败”。这种方式存在明显短板:
Salesforce 高级 AI 研究经理、论文作者 Shelby Heinecke 指出:
“我们已经过了‘如何部署代理’的阶段,现在需要解决的是:如何正确评估它们。”
MCP 作为连接 AI 与工具的标准协议,正在被广泛采用。而 MCPEval 的创新之处在于——利用 MCP 本身来评估基于 MCP 运行的代理。
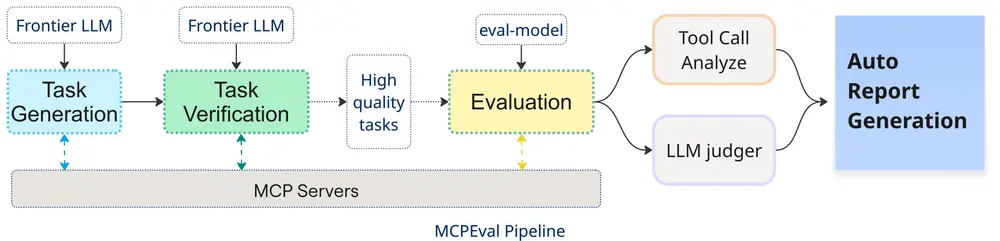
MCPEval 并非简单的打分工具,而是一套完整的评估闭环,具备三大核心优势:
整个流程无需人工干预,实现“配置即测试”。
传统评估止步于结果,而 MCPEval 提供全过程行为洞察:
这些数据不仅能用于评分,更能定位性能瓶颈,为模型微调提供高质量训练样本。
MCPEval 收集的高质量任务轨迹可直接用于:
Heinecke 将其定位为“评估与修复代理的一站式解决方案”。
MCPEval 的框架设计包含三个阶段:
| 框架 | 机构 | 侧重点 | 特点 |
|---|---|---|---|
| MCPEval | Salesforce | 协议级交互 | 基于 MCP,自动化生成任务,提供深度行为分析 |
| MCP-Radar | UMass Amherst & 西安交通大学 | 通用技能评估 | 聚焦软件工程、数学等通用领域,强调效率与准确性 |
| MCPWorld | Beijing University of Posts and Telecommunications | GUI 与系统级代理 | 支持图形界面、API 调用等复杂计算机使用场景 |
| AgentSpec | 新加坡管理大学 | 可靠性监控 | 提供代理行为规范与监控机制 |
| Galileo | 初创公司 | 工具选择质量 | 评估代理在多工具环境下的决策能力 |
MCPEval 的独特之处在于,它将测试环境与部署环境统一——代理在哪个 MCP 服务器上运行,就在哪个环境中被评估,确保了测试的真实性。













