
Midscene.js
Midscene.js 采用了多模态大语言模型(LLM),能够直观地“理解”你的用户界面并执行必要的操作。你只需描述交互步骤或期望的数据格式,AI 就能为你完成任务。
Memories.ai不只是让 AI “看到”视频,更是让它“记住”、理解并随时调用其中的每一个瞬间。如果说 GPT 让文本进入了智能时代,那么 LVMM 可能就是视频智能时代的起点。
一家由前 Meta 研究人员创立、获 800 万美元融资支持的 AI 实验室 Memories.ai,近日推出了一项可能重新定义视频理解的技术——大型视觉记忆模型(Large Visual Memory Model, LVMM)。
这不是又一个视频分析工具,而是一次对“AI 是否能真正拥有长期视觉记忆”的系统性突破。
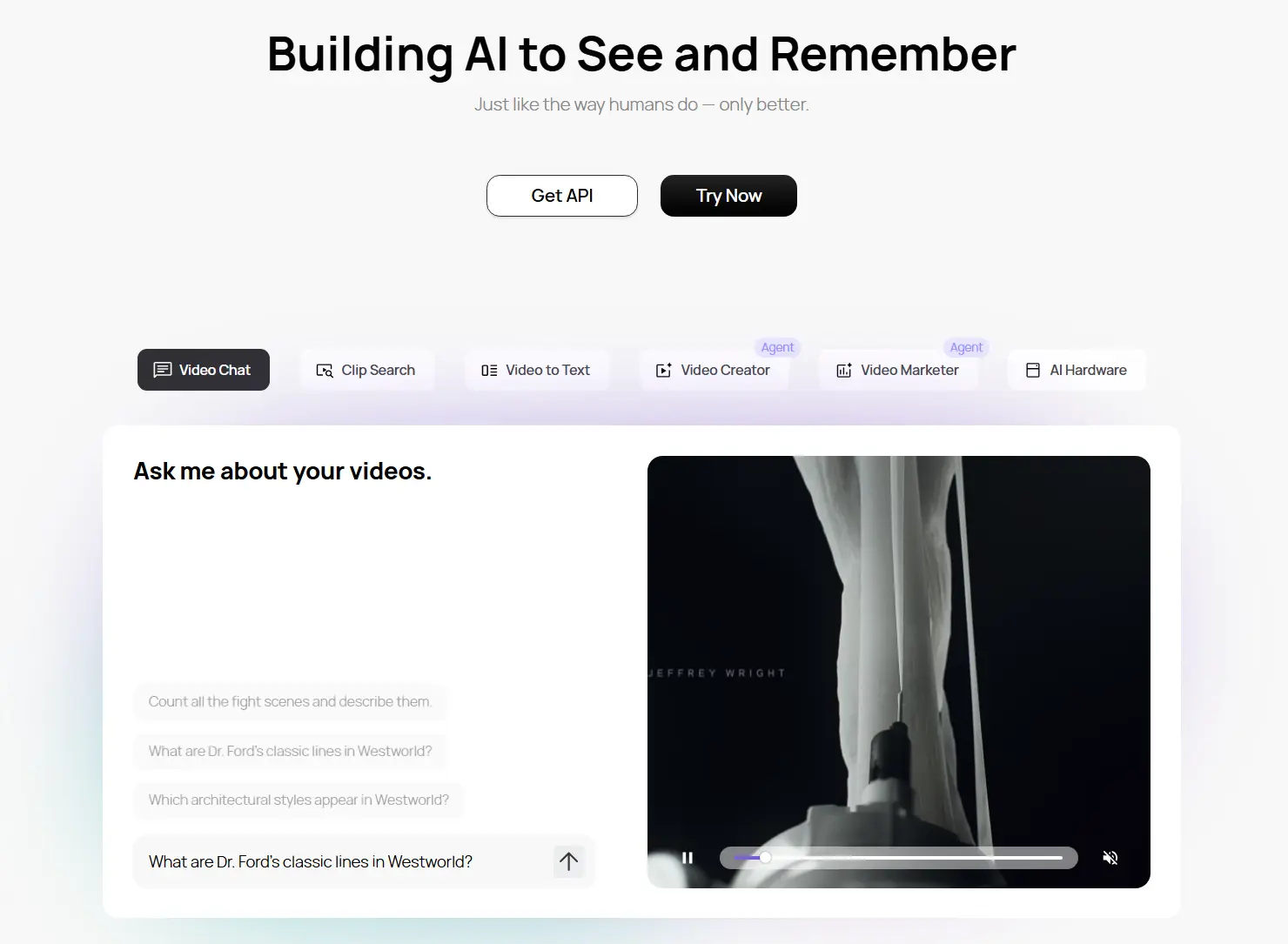
其核心目标直指当前主流 AI 的短板:大多数模型在处理长视频时会丢失上下文,无法持久记忆,更难以跨视频检索细节。
而 Memories.ai 的 LVMM 做到了:
将数小时、数天甚至数年的视频内容完整保留在“数字记忆”中,随时调用,帧级精确。
现有 AI 视频工具(如 Gemini、GPT-4o)通常受限于上下文长度,处理超过一小时的视频时,信息完整性急剧下降。它们更像是“临时浏览”,而非“长期记忆”。
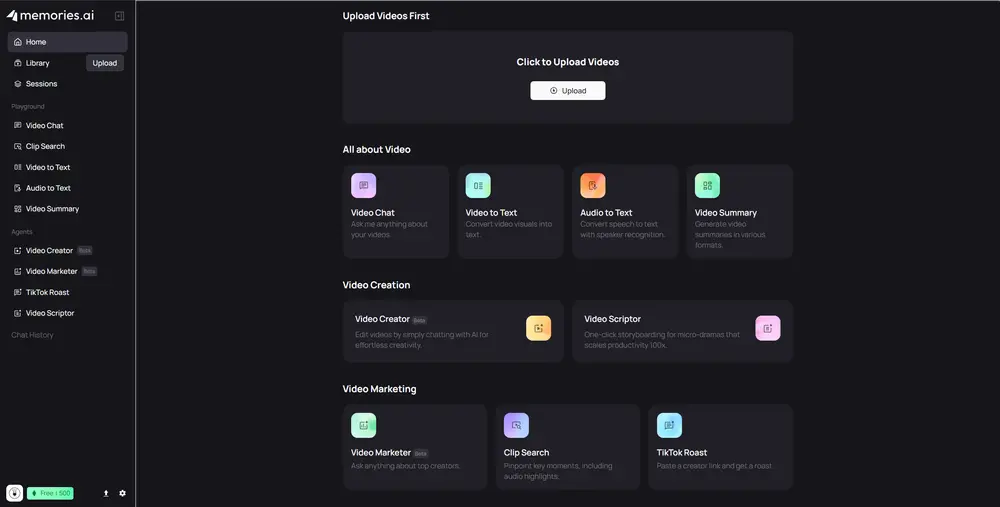
Memories.ai 则完全不同。它的 LVMM 模型受人类记忆机制启发,具备三项关键能力:
用户只需上传一次视频,即可在后续任意时间与其进行交互。
无需重复上传,上下文永不丢失。
你可以今天问“主角穿什么颜色的外套”,下周再问“他什么时候第一次提到复仇”,AI 仍能准确回答。
支持自然语言查询,瞬间定位视频中的特定时刻。例如:
系统不仅能识别动作和物体,还能结合时间、语境和人物身份进行综合判断。
不仅能识别“谁在说话”,还能在多人同时讲话、背景嘈杂、画面切换频繁的情况下保持高精度。
结合语音、面部特征、语调等多模态信号,实现跨镜头的身份追踪。
传统视频 AI 在长时程分析中常出现“幻觉”——即编造未发生的事件或错误匹配时间戳。
Memories.ai 的方法从根本上规避了这一问题:
这意味着,它不是“猜测”发生了什么,而是“回放”真实发生了什么。
团队将其能力概括为三个核心价值:
平台已提供 API 接口,开发者可基于 LVMM 构建:
Memories.ai 由多位前 Meta AI 研究人员创立,核心成员曾深度参与 Facebook 视频理解、AR/VR 场景建模等项目。其技术路线融合了认知科学与深度学习,强调“记忆结构”而非单纯“模型规模”。
800 万美元的种子轮融资已到位,资金将用于扩展模型训练、优化推理效率,并推动 API 生态建设。













