JadeAI
JadeAI是一款由 AI 驱动的智能简历生成器,结合了可视化的拖拽编辑与强大的大模型能力,让每个人都能轻松打造高质量简历。
在数据驱动的时代,从网页中提取结构化信息是一项常见但关键的任务。传统爬虫依赖 CSS 选择器或 XPath 规则,但面对结构复杂或不断变化的网页时,维护成本高、适应性差。
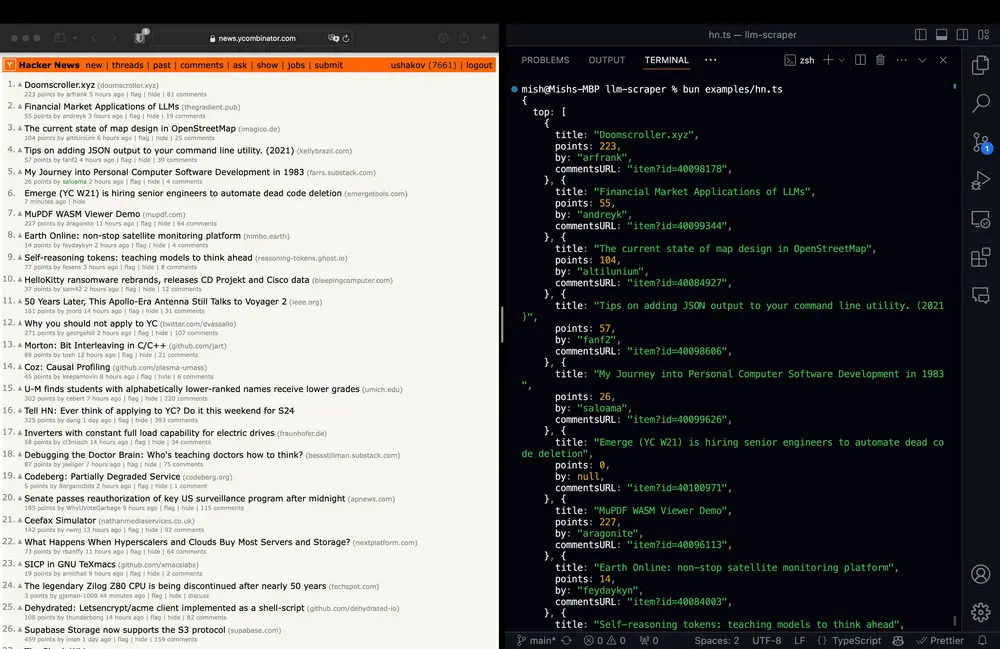
LLM Scraper 提供了一种全新的解决方案:使用大语言模型(LLM)从任何网页中智能提取结构化数据。
LLM Scraper 是一个基于 TypeScript 的开源库,它通过调用大语言模型(如 GPT、Gemini、Llama 等),将网页内容智能解析为结构化数据。无需编写 CSS 选择器,只需定义你想要的数据结构,LLM 就能自动从页面中提取相关信息。
最新版本:v1.6
LLM Scraper 最近更新至 1.6 版本,带来了多项改进和新功能:
LLM Scraper 在底层使用函数调用机制,将网页内容作为输入,由 LLM 模型理解页面结构,并输出符合你定义的结构化数据。
你可以在这里了解更多关于函数调用和数据提取的实现细节。
html:加载预处理后的 HTMLraw_html:加载原始 HTML(不进行预处理)markdown:加载 Markdown 格式内容text:提取纯文本(使用 Readability.js 优化内容提取)image:加载网页截图(仅限支持图像输入的多模态模型)LLM Scraper 适用于以下场景: