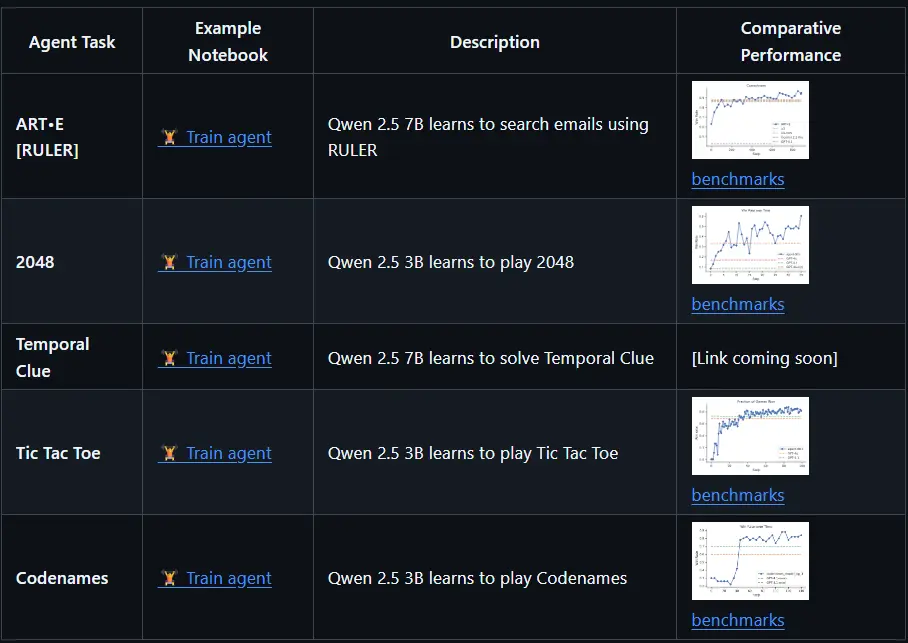
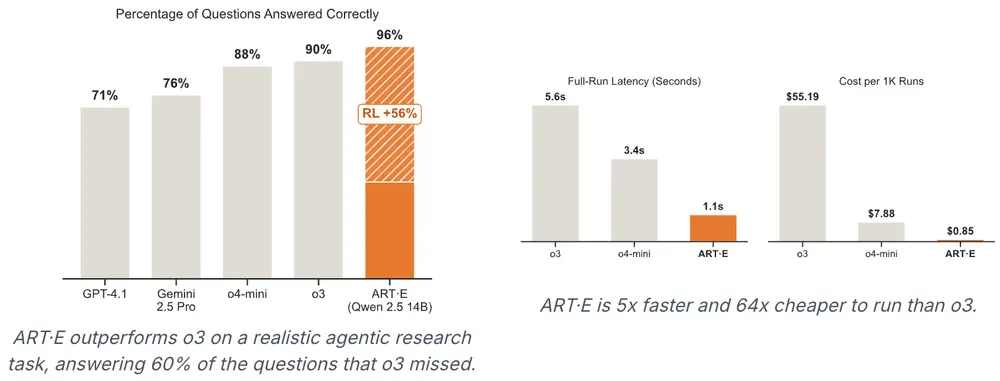
由OpenPipe推出,ART(Agent Reinforcement Trainer) 是一个专为训练多步骤智能体(Agent)的开源强化学习框架。它基于 GRPO(Group Relative Policy Optimization) 算法,支持 Qwen、Llama、Kimi 等主流语言模型,旨在提升大语言模型在现实任务中的表现力与稳定性。

ART 为开发者提供了一个模块化、易集成、低门槛的训练系统,适用于从邮件搜索、任务规划到游戏控制等多种场景。
项目亮点
- ✅ 支持多步骤 Agent 训练:适用于复杂任务流程
- ✅ 集成 GRPO 强化学习算法:高效提升模型表现
- ✅ 轻量模型优先:适合用作任务驱动模型(如 Qwen2.5-7B)
- ✅ 自动奖励机制 RULER:无需手动设计奖励函数
- ✅ 客户端-服务器架构:便于本地开发与远程训练分离
框架概述
ART 的核心目标是让开发者能够轻松为自己的智能体添加训练能力,从而提升其在多轮任务中的表现。
它通过客户端-服务器架构,将训练流程封装为服务,开发者只需专注于任务逻辑的实现,而无需关心底层训练细节。
为什么选择 ART?
✅ 简单易用的封装接口
- 提供与 OpenAI 兼容的客户端接口,轻松接入现有代码
- 抽象训练服务为模块化组件,无需修改业务逻辑即可启用训练
✅ 灵活部署支持
- 可在本地笔记本运行客户端,服务器自动启动 GPU 环境
- 支持本地 GPU 训练或远程训练集群部署
✅ 第三方平台集成
- 与 Weights & Biases(W&B)、Langfuse、OpenPipe 等平台无缝集成
- 支持日志追踪、可视化分析、性能监控等功能
✅ 可定制与默认配置并存
- 支持自定义训练参数(如 batch size、学习率等)
- 提供优化过的默认配置,开箱即用
RULER:无需人工设计的智能奖励机制
RULER(Relative Universal LLM-Elicited Rewards) 是 ART 提供的一种零样本奖励生成机制,它利用大语言模型作为“评判者”,自动为智能体轨迹打分。
RULER 的核心优势:
- 2-3 倍开发效率提升:无需手动设计奖励函数
- 任务通用性:适用于任何任务,无需额外标注数据或专家反馈
- 性能优异:在 3/4 的基准测试中,表现优于人工设计奖励
- 无缝集成:可直接替换传统奖励函数,降低开发成本
训练循环流程
ART 的训练流程分为两个主要阶段:推理 与 训练,循环执行直至达到预设迭代次数。
🔍 推理阶段
- 你的代码通过 ART 客户端执行 Agent 工作流(支持并行轨迹采集)。
- 请求被转发至 ART 服务器,服务器使用 vLLM 运行当前模型的 LoRA。
- 每次交互(系统、用户、助手)被记录为一条 轨迹(Trajectory)。
- 轨迹完成后,你的代码为其分配一个 奖励值,用于后续训练。
🛠️ 训练阶段
- 所有轨迹按组提交至服务器。
- 服务器暂停推理,使用 GRPO 算法进行训练。
- 新模型被保存为 LoRA,并加载至 vLLM。
- 推理恢复,进入下一轮训练循环。
📦 支持模型
ART 支持主流大语言模型系列,包括但不限于:
- Qwen 系列:Qwen2.5、Qwen3
- Llama 系列:Llama3、Llama-3.1
- Kimi 系列
- 其他兼容 LLaMA 架构的模型