
ClawBridge
ClawBridge 是专为 OpenClaw Agent 打造的 Mobile Dashboard(移动端仪表盘)。它不仅是您的随身 Mission Control(任务控制台),还能让您通过手机实时监控 Agent 的思考过程、追踪 Token 成本、管理后台 Cron 任务。
在AI领域,通用大语言模型(LLMs)一直是行业的焦点。然而,这些“巨无霸”模型虽然强大,却往往过于复杂、昂贵且低效,难以满足许多实际生产需求。位于帕洛阿尔托的初创公司Fastino选择了一条不同的路径:通过开发小巧、高效的任务特定语言模型(TLMs),为开发者和企业提供了更精准、更经济的解决方案。
近日,Fastino宣布完成由Khosla Ventures领投的1750万美元种子轮融资,总融资额接近2500万美元。这一支持不仅彰显了投资者对Fastino技术的认可,也预示着小型化、任务特化的AI模型可能正在成为行业新趋势。
Fastino的任务特定语言模型(TLMs)专为需要低延迟、高准确性AI的企业和开发者设计,适用于各种生产级任务。与通用LLMs不同,TLMs专注于解决具体问题,避免了冗余参数和不必要的复杂性。这种设计理念使它们能够在低端硬件上高效运行,同时保持卓越的性能。
当前AI领域的痛点显而易见:尽管通用LLMs功能强大,但它们对于许多目标明确的生产用例来说过于臃肿且效率低下。大多数企业需要的是精确性、速度和可扩展性,而非通用推理能力。Fastino正是基于这一洞察,开发了TLMs——一种比大型通用模型更快、更准确、成本效益更高的解决方案。
这些模型经过优化,能够无缝集成到生产环境中,注重可预测的性能和开发者效率,为企业提供了一种更具性价比的选择。
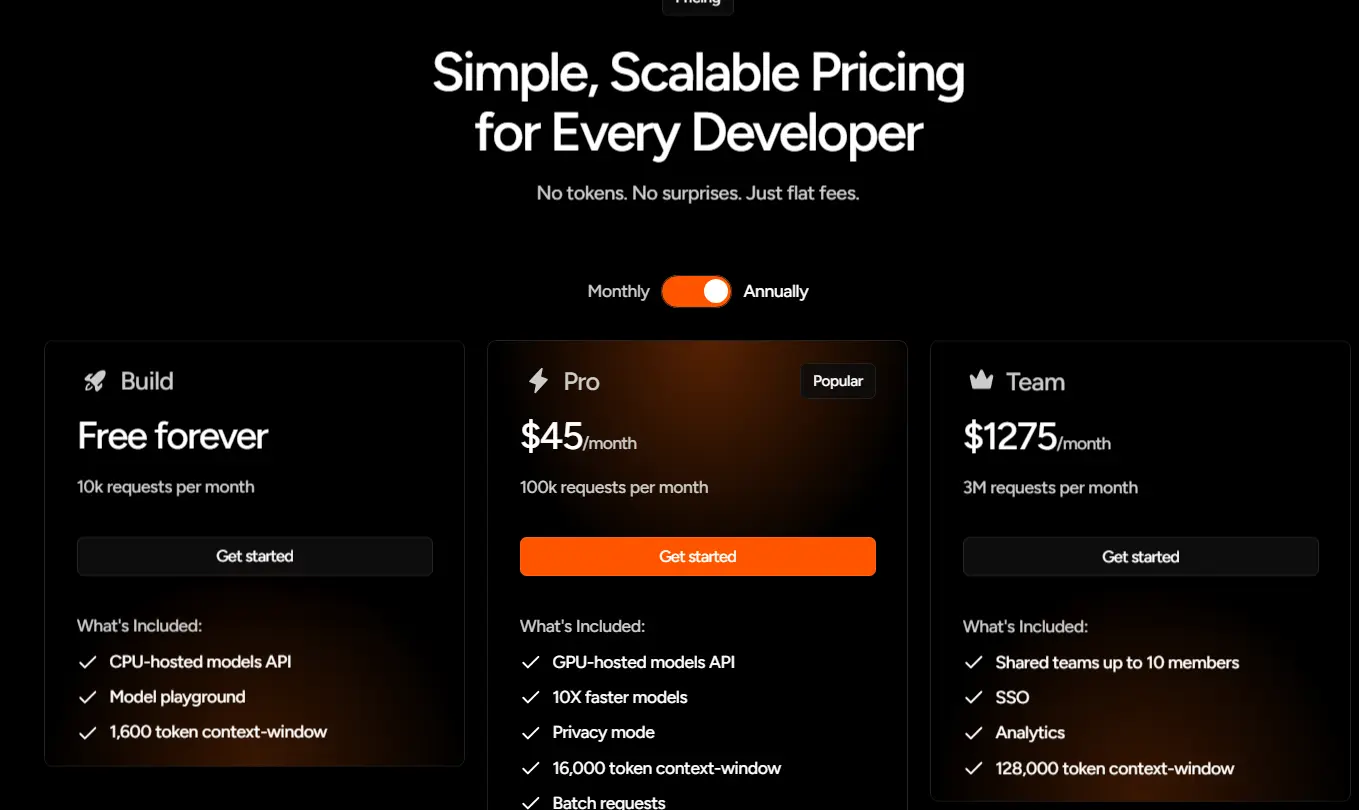
Fastino的首批TLM系列涵盖多个企业和开发者的核心任务,每个模型都针对特定场景进行了深度优化:
每个TLM都经过精心设计,确保无浪费标记、无需为通用智能支付额外费用,真正实现了“按需定制”。
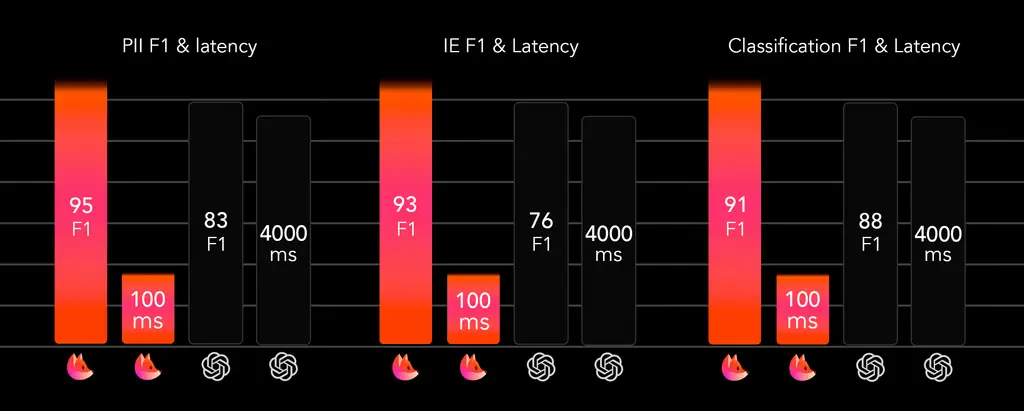
为了验证TLMs的性能,Fastino创建了一套基于真实客户用例的内部基准测试。结果显示,TLMs不仅更小、更快,在关键任务上的表现也优于通用LLMs。
Fastino的PII删除模型在医疗、金融、政府和电商等多个领域的测试中表现出色。无论是卡号、社保号还是职位、联系信息,该模型都能以毫秒级延迟提供业界领先的准确性,全面覆盖所有类型的PII。
在信息提取任务中,Fastino的TLM在从表单、聊天和文档中提取结构化数据时展现了显著优势。与GPT-4o等通用模型相比,Fastino的信息提取模型在F1分数上提升了[x%]。
Fastino的分类器无需提示工程或调优即可提供高准确性和低于100毫秒的延迟,适用于实时内容审核、LLM代理防护、路由和安全系统。
Fastino的TLMs基于一种新颖的方法,利用Transformer的注意力机制,但在架构、预训练和后训练层面引入任务特化。这种设计优先考虑紧凑性、运行时适应性和硬件无关的部署,同时不牺牲任务准确性。
通过系统性地消除参数冗余和架构低效,Fastino的模型能够在低端硬件(如CPU或低端游戏显卡)上高效运行。由于其轻量且快速的特性,这些模型可以直接嵌入到因延迟或成本限制而无法使用LLMs的应用程序中。
Fastino相信,AI的价值在于其特化、快速且精准的部署能力。TLMs不仅是下一代智能系统的基石,还将推动分布式、容错、高效的AI系统的发展,为从云端到移动端再到边缘设备的嵌入式AI功能提供强有力的支持。
通过专注于小而美的模型,Fastino正在重新定义AI应用的可能性。在这个充满竞争的行业中,Fastino或许能证明,小模型也能带来大变革。













