UltraReal Fine-Tune 是基于 FLUX.1-dev 模型的一个微调版本,旨在通过训练者自己的 UltraReal LoRA 并扩展更大的数据集,找到业余美学与专业高质量视觉效果之间的最佳平衡点。该模型的目标是将现实主义推向新的高度,同时确保在各种应用场景中保持一致的高质量输出。
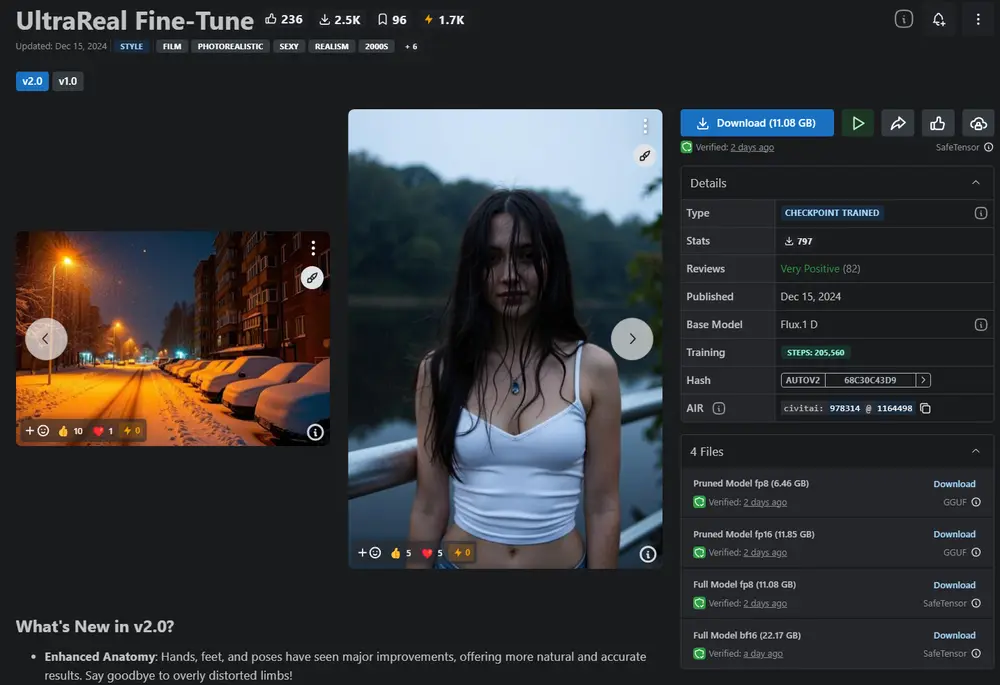
v2.0 新特性
增强的解剖结构:
- 手、脚和姿势得到了显著改进,呈现出更自然和准确的效果。
- 有效解决了之前版本中常见的过度扭曲四肢问题,使生成的人物更加真实可信。
改进的纹理与质量:
- 皮肤细节更加丰富,整体纹理更加细腻,结果更加清晰。
- 虽然偶尔仍可能出现模糊图像,但相比之前的版本或单独使用 LoRAs 时,这种情况已大幅减少。
改进的文字渲染:
- 在图像中生成文字的能力有所提升,效果比以前更好。
- 然而,仍可能出现奇怪的符号或不完整的单词等瑕疵,这仍然是持续改进的工作。使用 t5xxl fp16 而不是 fp8 可以显著改善文字生成效果。
扩展的数据集:
- 使用了更大、更多样化的数据集(1800 张图像),带来了更平衡的风格、光线和构图。
- 这使得模型能够更好地处理不同类型的输入,提供更加多样化和高质量的输出。
新增的模型变体:
- BF16:适用于需要高精度的场景。
- FP8:适用于资源有限的环境,但可能会影响部分细节。
- Quant 8 (Q8):在质量上略优于 FP8,能够在保持资源需求可控的同时提供更精细的细节。
- Quant 4 (Q4):适用于极端资源受限的环境,虽然细节稍逊,但仍然表现良好。
根据测试,Quant 8 (Q8) 是推荐的选择,因为它在质量和资源需求之间取得了良好的平衡。
已知限制
NSFW 能力:
- 在本版本中,NSFW 内容的生成能力仍然是一个薄弱环节。
- 专注于 NSFW 内容的微调已经在进行中,未来版本将对此进行改进。
文字渲染:
- 尽管文字生成有所改进,但偶尔仍可能出现奇怪的符号或不完整单词等瑕疵。
- 使用 t5xxl fp16 可以显著改善文字生成效果。
最佳结果提示
为了获得最佳的生成效果,建议遵循以下提示:
- 采样器:使用 DPM++ 2M 采样器,以获得平滑且一致的输出。
- 步数:目标为 30–50 步,以捕捉更精细的细节而不过度处理。
- 调度器:Beta 调度器仍然是此 Checkpoint 的最佳选择。
提示技巧
最佳的提示风格应涉及复杂且清晰、用逗号分隔的短语。虽然你可以通过故事性提示发挥创意,但像“这种垃圾让她的风格更复古”这样不必要的描述并不会改善结果。保持简洁且描述性,专注于关键的视觉细节以获得最佳输出。
未来计划
我致力于进一步开发此微调模型。下一个更新可能会专注于:
- 扩展 NSFW 能力:提高在生成 NSFW 内容时的质量和多样性。
- 增强动态姿势和光照场景等边缘案例:改进模型在处理复杂姿势和光照条件下的表现。
- 改进文字渲染:继续优化文字生成,以获得更清晰、更准确的结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











