
在 AI 智能体(Agentic)应用爆发的今天,延迟已成为制约用户体验的终极瓶颈。当 GPU 还在通过堆叠 HBM(高带宽内存)和复杂封装来试图突破“内存墙”时,一家成立仅 2.5 年的初创公司 Taalas 选择了一条更为激进的道路:彻底抛弃通用计算,将 AI 模型直接“硬连线”(Hard-wiring)到硅片电路中。

核心突破:模型即电路,物理层消除延迟
Taalas 的技术逻辑简单而疯狂:融合计算与存储。
- 硬连线架构: 不同于 Cerebras 或 Groq 试图通过集成 SRAM 来加速,Taalas 开发了一种平台,能将任意 AI 模型的神经网络直接映射为定制 ASIC 电路。
- 消灭内存墙: 在这种设计下,计算直接在 DRAM 级密度的电路中完成,彻底摒弃了昂贵的 HBM、复杂的 2.5D/3D 封装以及庞大的散热系统。数据无需在处理器和内存之间搬运,从物理层面消除了传输延迟。
- 极致能效: 由于去除了冗余的数据移动和通用控制逻辑,其能效比和成本控制达到了前所未有的高度。
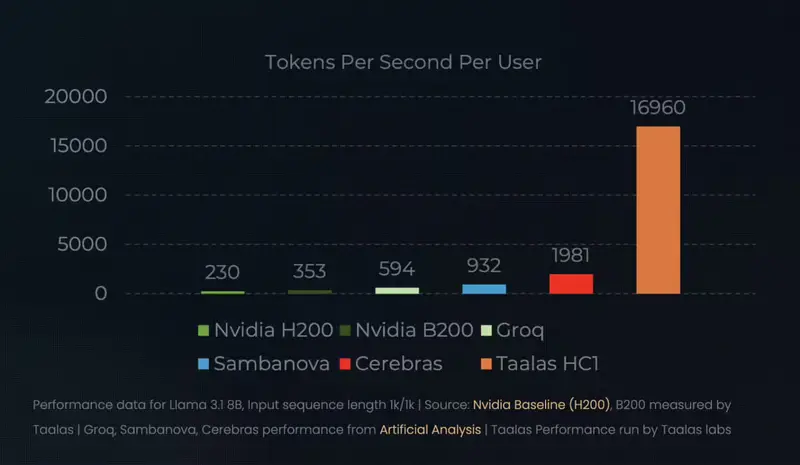
性能实测:17000 TPS 的恐怖速度
Taalas 已展示其首款产品 HC1 芯片,专为 Meta 的 Llama 3.1 8B 模型定制。
- 规格参数: 采用台积电 6nm 工艺,芯片面积高达 815 mm²,与 NVIDIA H100 相当。
- 推理速度:
- 公开演示(EE Times):超过 15,000 Tokens/s。
- 内部测试(激进量化版):接近 17,000 Tokens/s。
- 对比: 这一速度是当前高端 GPU 集群的 10 倍 以上。
- 集群扩展: 针对更大模型(如 DeepSeek R1),Taalas 通过 30 颗芯片集群,实现了 12,000 TPS/User 的吞吐量。相比之下,现有 GPU 方案通常仅为 200 TPS/User。这意味着在实时语音交互、复杂推理等场景中,用户将获得近乎零延迟的丝滑体验。
- 成本优势: 官方宣称,其生产成本仅为现有高端算力方案的 1/20。
代价与妥协:速度换容量,固定换灵活
然而,极致的速度并非没有代价。Taalas 的技术路线面临着明显的物理限制和商业挑战:
1. 参数密度的妥协
巨大的 815 mm² 芯片仅能容纳 80 亿参数 的模型。这与当前动辄万亿参数的前沿模型相比,显得“容量捉襟见肘”。为了实现电路级的并行计算,Taalas 在单位面积的参数密度上做出了巨大牺牲。这意味着该技术目前更适用于中小参数量的专用模型,而非通用超大模型。
2. “一次性”硬件的困境
这是 Taalas 商业模式面临的最大挑战:模型权重被固化在硅片中。
- 无法更新: 芯片一旦制造完成,其运行的模型版本即被锁定。如果 Llama 3.2 发布,基于 Llama 3.1 定制的 HC1 芯片将无法升级,瞬间面临“淘汰”风险。
- 客户风险: 客户必须为特定模型版本购买专用硬件。在 AI 算法以月甚至周为单位迭代的今天,这种“硬件绑定软件”的模式极易导致资产贬值。

专用化的终局还是过渡?
Taalas 的出现,揭示了 AI 算力发展的一个极端方向:当软件算法趋于稳定,硬件专用化将是效率的终极答案。
- 适用场景: 对于已经成熟、不再频繁变动的模型(如特定的翻译模型、垂直领域的客服模型、边缘端的小模型),Taalas 的方案具有毁灭性的竞争优势。
- 局限性: 对于需要持续训练、快速迭代的通用大模型,这种“硬连线”方案显得过于僵化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











