
关于谷歌下一代图像生成模型“Nano Banana 2”的信息,近期在开发者社区引发关注。尽管尚未官方发布,但通过内部测试、平台泄露与代码提交记录,可梳理出以下已知进展。
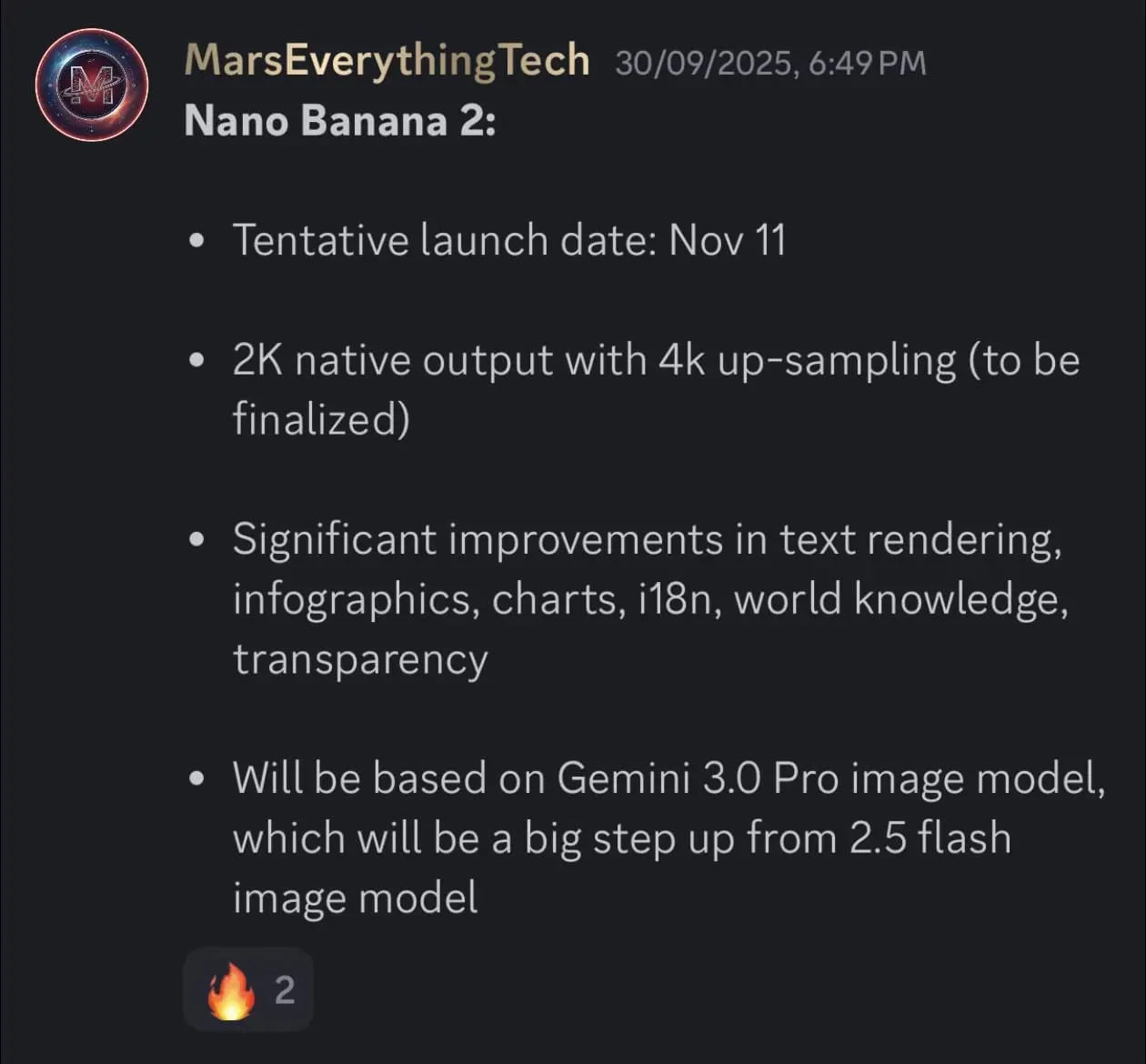
目前,该模型仍处于测试阶段。有迹象表明,其早期版本曾在 Media AI 平台短暂开放预览,输出结果与此前在 Gemini 应用中测试的版本一致。值得注意的是,当前测试版本仍基于 Gemini 2.5 Flash,而非传闻中的 Gemini 3.0 Pro。这暗示谷歌可能采取“分阶段发布”策略:先上线功能增强的中间版本,待底层基础模型成熟后再全面升级。

在能力层面,测试样本显示模型在以下方面有明显改进:
- 图像细节控制:能更准确地处理复杂着色、视角调整与构图;
- 文本生成校正:对图像中嵌入文字的识别与生成准确性提升;
- 多步骤生成流程:首次引入“规划—生成—审查—迭代”的闭环机制,模型会主动识别输出中的不一致或错误,并进行修正,而非一次性输出;
- 输出分辨率扩展:支持从 1K 到 4K 的多种分辨率,宽高比覆盖 1:1 至 21:9,提升在设计与媒体场景中的适用性。
GitHub 上的提交记录显示,该项目内部代号已更新为 “Nano Banana Pro”,并标注其指令遵循能力较早期版本提升约三倍。在“碎片化重建”等高难度测试中,模型展现出跨会话保持输出一致性的能力——这是前代产品难以实现的。

此外,谷歌计划将该模型扩展至 Whisk 实验室等其他实验平台,延续其多产品线协同推进的策略。
关于其底层架构,目前仍无定论。有猜测认为它可能基于 Imagen 4,也有观点认为仍会沿用 Gemini 系列架构。目前尚无证据表明其已完全切换至 Gemini 3.0 Pro。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











