
在生成式 AI 快速发展的今天,企业对 检索增强生成(RAG) 的需求日益增长。而在这个背后默默支撑的“幕后英雄”——嵌入模型(Embedding Model),也迎来了前所未有的关注。
近日,法国知名 AI 初创公司 Mistral AI 正式发布了其首款面向代码任务的嵌入模型:Codestral Embed。这款模型一经推出,就在多个基准测试中表现亮眼,甚至宣称在实际场景中超越了 OpenAI 和 Cohere 等行业领先者。
什么是嵌入模型?为什么它很重要?
简单来说,嵌入模型的作用是将文本、代码或数据转换成向量(数值表示),这样 AI 就可以快速查找相似内容,从而提升信息检索效率。
这在以下场景中尤为关键:
- RAG(检索增强生成):让 AI 在回答问题前先从知识库中找到相关信息;
- 语义搜索:用自然语言查找代码片段;
- 代码分析:识别重复代码、检测模式等;
- 相似性匹配:找出功能相近的代码块。
换句话说,好的嵌入模型 = 更快、更准的信息检索能力,这对开发工具、代码平台和智能助手至关重要。
Codestral Embed 的核心优势
✅ 专为代码设计,性能拔尖
Codestral Embed 是 Mistral Codestral 模型家族的一员,专门针对代码场景进行训练和优化。
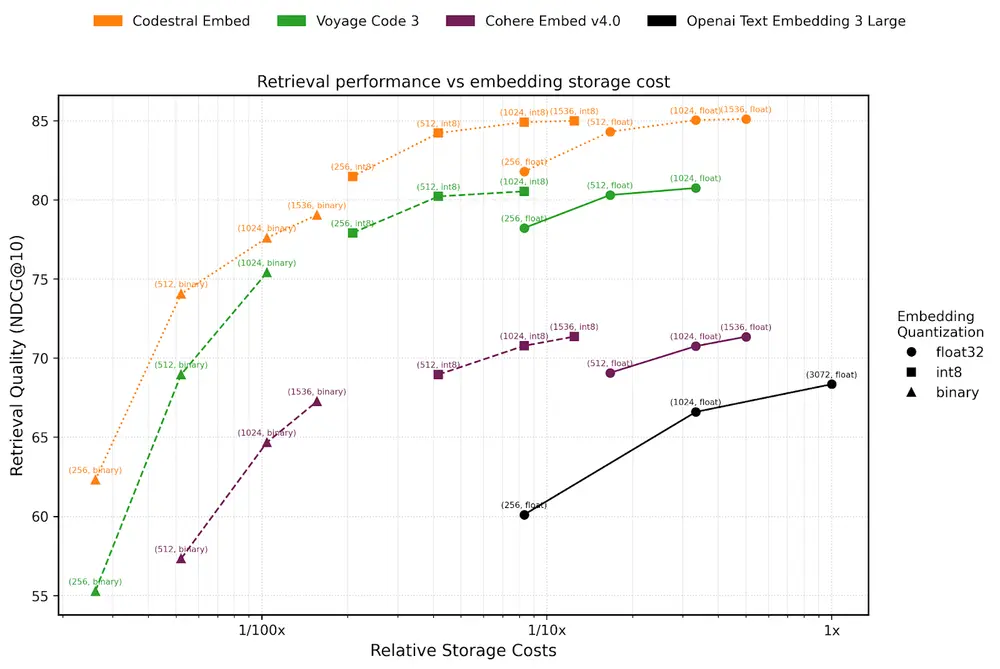
根据 Mistral 官方博客披露的数据,该模型在以下方面表现出色:
- 在 SWE-Bench 和 GitHub Text2Code 基准测试中均优于现有主流嵌入模型;
- 超过 Cohere Embed v4.0 和 OpenAI 的 Text Embedding 3 Large;
- 支持多种维度输出(如 256 维、512 维),兼顾性能与成本;
- 使用 int8 精度压缩后仍保持领先表现,适合资源有限的部署环境。
一句话总结:Codestral Embed 不只是写得像人写的 SQL,而是能在真实数据库里跑出结果。
✅ 可灵活控制精度与成本
Mistral 表示,Codestral Embed 的嵌入维度按相关性排序,用户可以根据需要选择保留前 n 个维度,实现质量与成本之间的平滑权衡。
例如:
- 使用 256 维 + int8 精度时,存储空间大幅减少,但依然优于竞品;
- 若追求最高精度,可使用完整维度输出。
这对于企业级应用尤其重要:既能节省资源,又不牺牲效果。
主要应用场景一览
Codestral Embed 并不是一款“纸上谈兵”的模型,它的目标非常明确:服务真实世界的开发需求。以下是几个典型用例:
1️⃣ RAG 场景下的高效检索
- 提升 AI 在复杂知识库中的响应速度;
- 减少无效查询,提高准确性;
- 特别适用于文档系统、编码助手等场景。
2️⃣ 语义代码搜索
- 开发者可以用自然语言查找代码片段;
- 如:“帮我找一个 Python 中处理时间戳的函数”。
3️⃣ 相似性代码匹配
- 识别重复代码或结构相似的函数;
- 对于大型项目、代码规范管理非常有用。
4️⃣ 代码聚类与分析
- 根据语义或功能对代码进行分组;
- 帮助发现架构模式、识别异常模块。
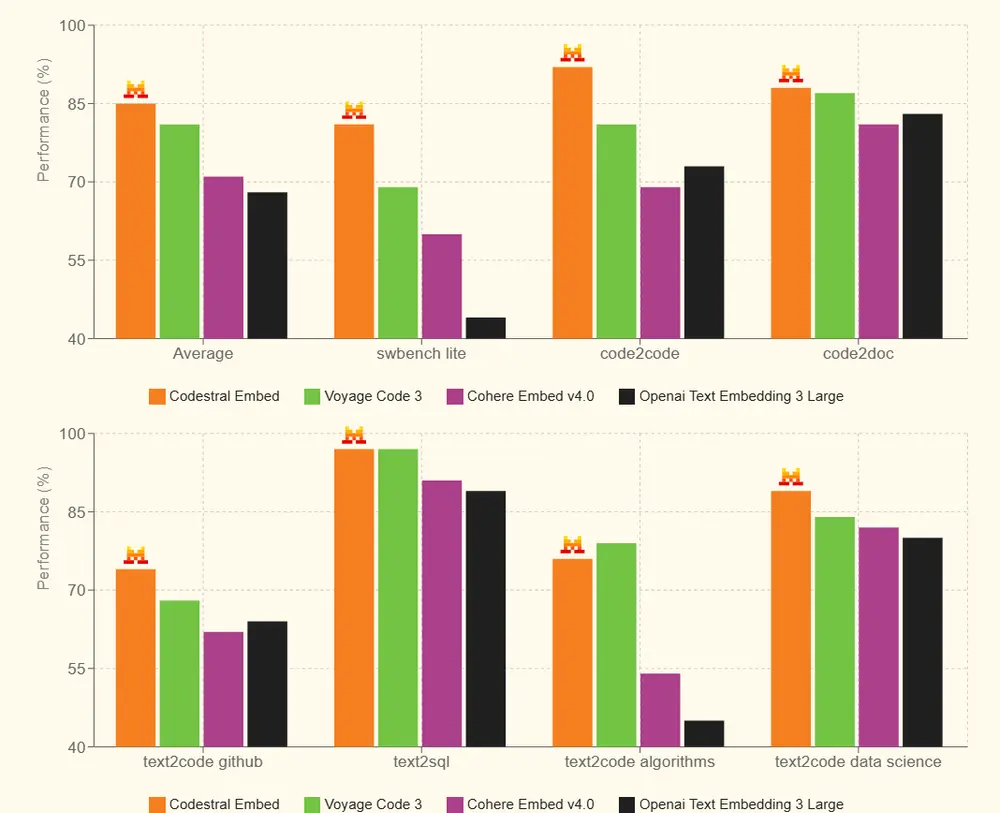
📈 Mistral 的战略意图:持续加码开发者生态
Mistral 最近动作频频,不仅推出了 Codestral Embed,还上线了:
- Mistral Medium 3:旗舰大模型的中等版本,专为企业级平台 Le Chat Enterprise 设计;
- Agents API:支持构建多代理协作系统的工具链;
- 一系列面向开发者的新产品和开源项目。
这些动作表明,Mistral 正在努力打造一个以开发者为中心的 AI 生态体系,希望在激烈的竞争中脱颖而出。
嵌入模型市场竞争加剧
尽管 Mistral 的新模型在性能上展现出优势,但它所面对的市场并不轻松:
- 封闭阵营:如 OpenAI、Cohere,拥有成熟的生态系统和商业客户;
- 开源阵营:如 Qodo 的 Qodo-Embed-1-1.5B,主打免费和开放;
- 定制化需求:部分企业希望基于自有数据训练专属嵌入模型。
不过,Mistral 的优势在于:
- 法国背景 + 欧洲市场加持,更适合注重隐私与合规的企业;
- 模型小巧、高效、支持灵活配置;
- 价格亲民:每百万 token 仅需 0.15 美元。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











