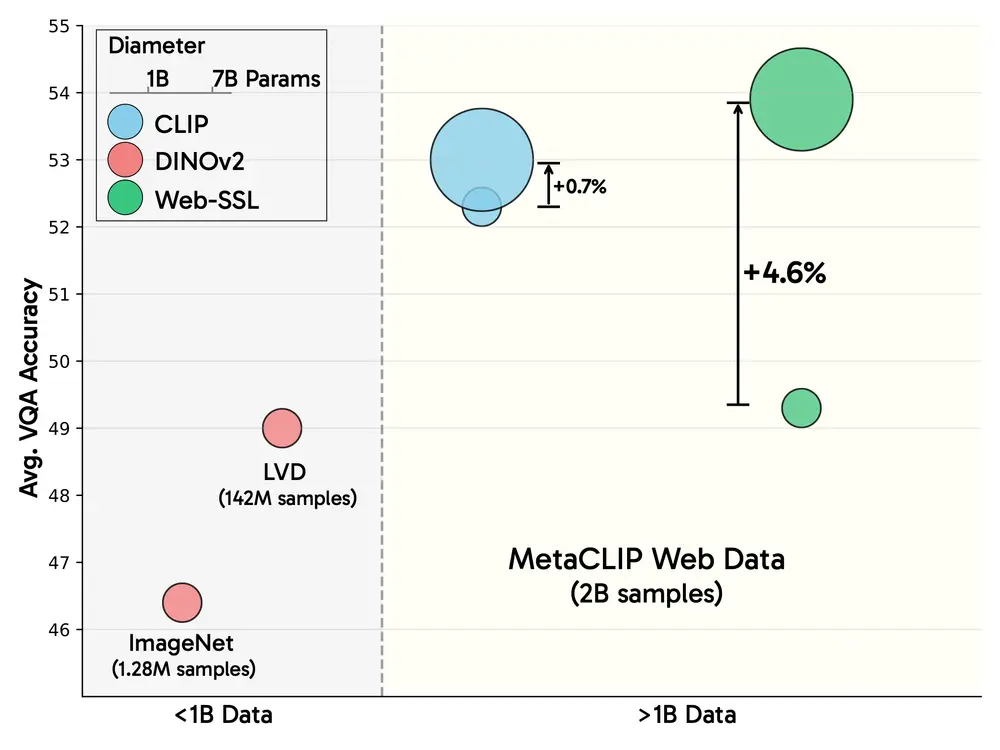
Meta发布Web-SSL系列模型:无语言也能学视觉,探索纯视觉自监督学习的潜力近年来,对比语言-图像模型(如CLIP)在多模态任务中表现出色,成为学习视觉表征的主流选择。这些模型通过大规模的图像-文本对进行训练,利用语言监督来融入语义信息,广泛应用于视觉问答(VQA)、文档理解...大语言模型# Meta# Web-SSL11个月前02720