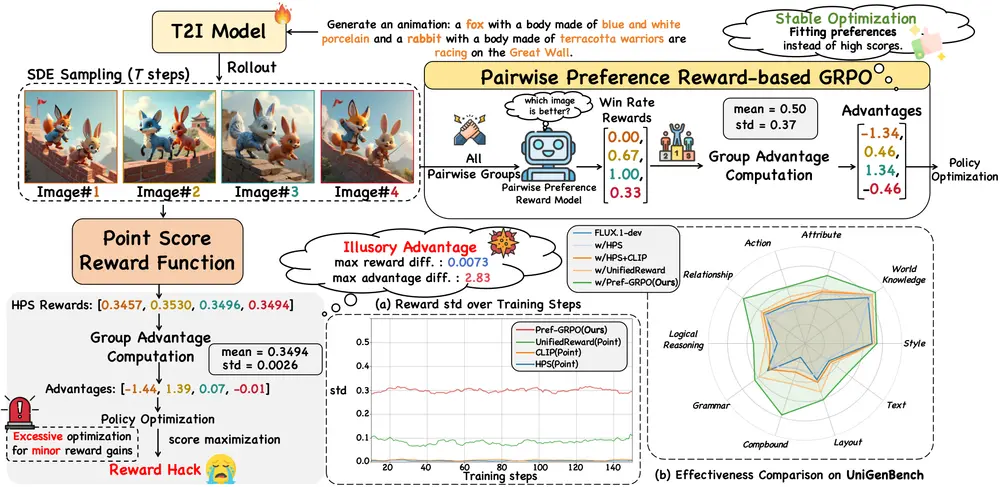
复旦等团队联合突破文生图模型生成瓶颈:Pref-GRPO解决奖励操控,UniGenBench补上评估短板文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准...图像模型# Pref-GRPO# 文生图模型7个月前03370