亚马逊计划推出「推理模型」,挑战 OpenAI 和 DeepSeek据 Business Insider 报道,亚马逊正在开发自己的推理模型,以在 AI 市场中与 OpenAI、Anthropic 和 DeepSeek 等公司展开竞争。这一新模型将通过亚马逊的 AWS...早报# DeepSeek# OpenAI# 亚马逊1年前02880
360推出Light-R1-32B:通过SFT和DPO以低成本超越DeepSeek-R1-Distill-Qwen-32B在数学竞赛 AIME24 上,尽管许多研究者尝试在 72B 或更小的模型上复现 DeepSeek-R1-Distill-Qwen-32B 的 72.6 分,但一直未能成功。 模型 集成模型 推出日期 ...大语言模型# 360# Light-R1-32B# 推理模型1年前03860
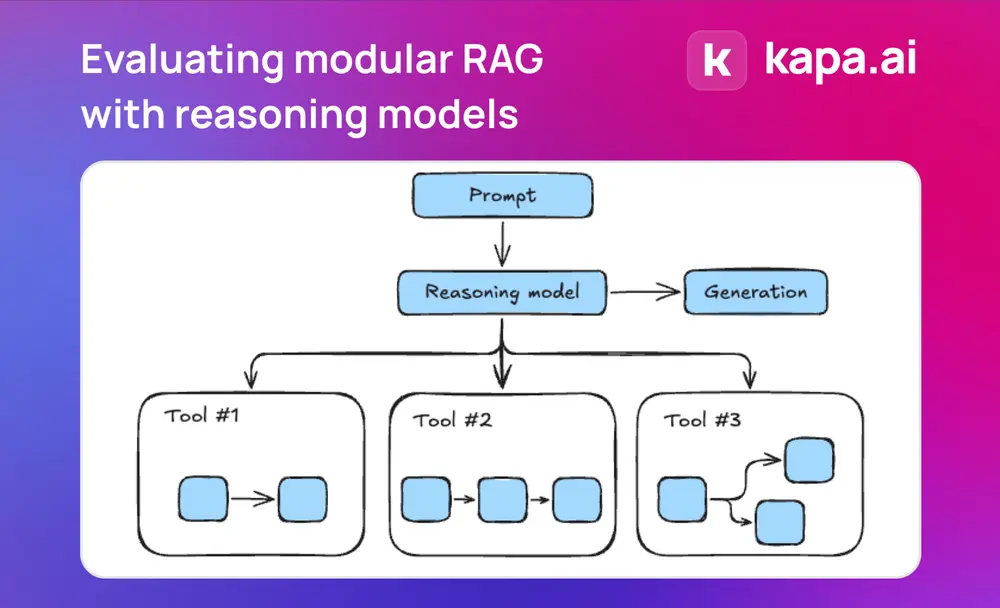
用推理模型评估模块化RAG:推理模型在核心检索任务中尚未超越传统RAG管道在检索增强生成(RAG)系统中,kapa.ai一直在探索如何利用最新的技术提升系统的性能和适应性。最近,它们团队尝试将OpenAI的o3-mini推理模型融入RAG管道,希望借助其强大的推理能力优化信...科普# RAG# 推理模型# 检索增强生成1年前02600