
GeekAI
GeekAI 基于 AI 大语言模型 API 实现的 AI 助手全套开源解决方案,自带运营管理后台,开箱即用。集成了 OpenAI, Claude, 通义千问,Kimi,DeepSeek,Gitee AI 等多个平台的大语言模型。集成了 MidJourney 和 Stable Diffusion AI 绘画功能。
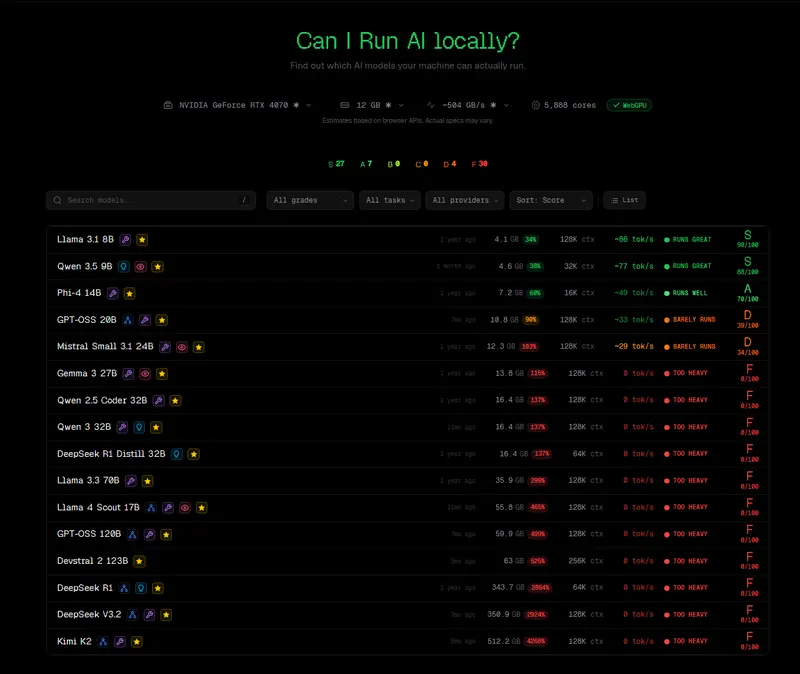
CanIRun.ai 是一个完全在浏览器端运行的免费工具,无需安装任何软件,无需上传任何数据,即可精准告诉你:你的机器到底能跑哪些 AI 模型,以及跑得有多快。
想在本地运行 Llama 3、Qwen 或 Mixtral 等大语言模型,却不确定自己的电脑配置是否达标?显存够不够?推理速度会不会慢如蜗牛?
CanIRun.ai 是一个完全在浏览器端运行的免费工具,无需安装任何软件,无需上传任何数据,即可精准告诉你:你的机器到底能跑哪些 AI 模型,以及跑得有多快。
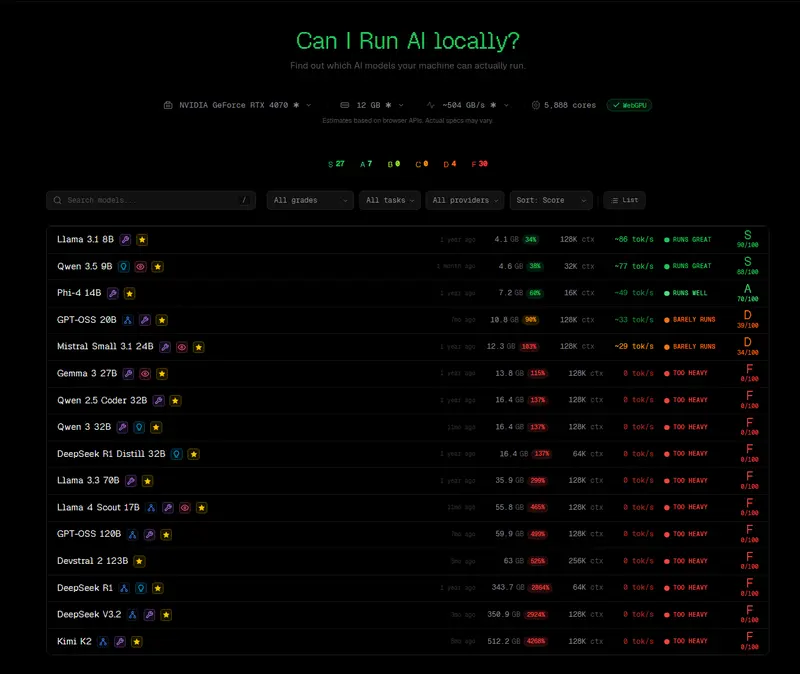
CanIRun.ai 不仅简单回答“能”或“不能”,还提供详细的性能预测:
CanIRun.ai 还提供了详尽的文档,用通俗语言解释了本地部署 AI 的关键概念,是新手入门的绝佳指南:
| 术语 | 通俗解释 | 关键影响 |
|---|---|---|
| 参数 (Parameters) | 模型的“脑细胞”数量。7B=70 亿,70B=700 亿。 | 参数越多越聪明,但越吃内存、越慢。7B 适合基础任务,70B+ 需高端显卡。 |
| 量化 (Quantization) | 压缩模型精度(如从 16 位降到 4 位)。 | 大幅降低显存需求,速度更快,智能度损失极小。本地运行必选! |
| 显存 (VRAM) | 显卡上的专用内存。 | 决定性因素。模型文件必须能完整塞进显存,否则速度暴跌至 CPU 水平。 |
| 混合专家 (MoE) | 如 Mixtral 8x7B,总参数大但每次只用一部分。 | 质量高、速度快,但显存占用依然按总参数算(这是坑!)。 |
| 上下文长度 | 模型一次能“记住”多少字。 | 越长越吃内存。本地通常 4K-8K 够用,128K 需巨大内存。 |
| 每秒词元 (Tok/s) | 生成速度。 | >30 流畅,>60 丝滑,<5 难以交互。 |
| GGUF 格式 | 本地运行的标准文件格式。 | 找模型时认准 .gguf 后缀,专为 CPU/GPU 混合推理优化。 |
| 内存带宽 | 数据从内存读入核心的速度。 | 速度瓶颈所在。Mac Studio 或 RTX 4090 快,主要因为带宽大。 |
llama.cpp 命令,一眼看懂自己的电脑能干什么。












