
OpenClaw 一键部署工具
OpenClaw 一键部署工具是一款专为 AI 爱好者和开发者打造的私人 AI 助手一键部署工具,支持多模型、多消息渠道接入,提供图形界面与命令行两种部署方式,无需复杂的手动配置,就能快速搭建属于自己的跨平台 AI 助手,兼具灵活性与实用性。
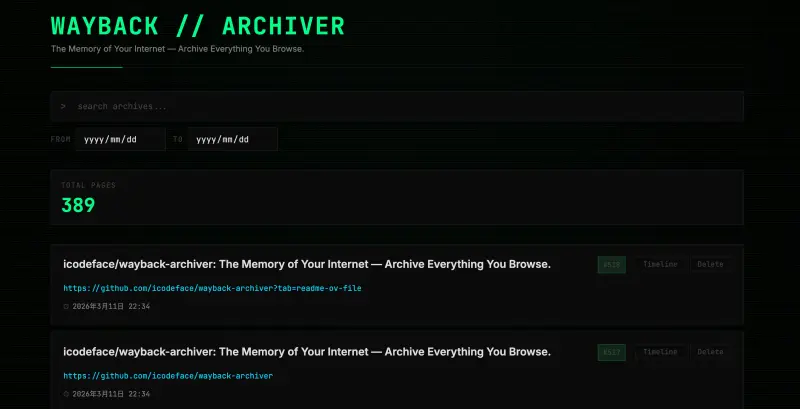
Wayback Archiver是一个自托管的个人网页归档系统,自动捕获并保存你在 Chrome 中浏览过的网页 — HTML、CSS、JavaScript、图片等一应俱全。当原始网页无法访问时,你仍然可以通过归档副本还原当时的页面样式和内容。
你是否曾遇到过这样的遗憾:一篇珍贵的文章突然被删除,一个重要的参考页面显示 404,或者你想回顾几个月前某个网站的特定版本却无从下手?
Wayback Archiver 是一个自托管的个人网页归档系统,它能自动捕获并保存你在浏览器中访问过的每一个网页——包括 HTML、CSS、JavaScript、图片和字体。当原始网页消失或改变时,你依然可以通过本地的归档副本,完美还原当时的页面样式和内容。
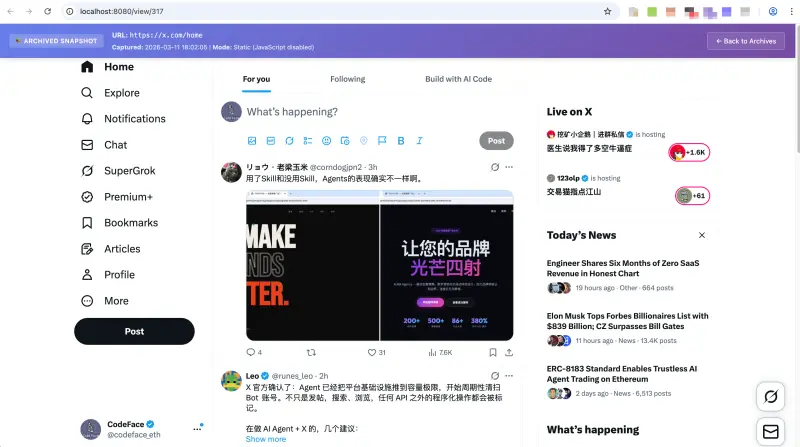
与简单的截图工具不同,Wayback Archiver 致力于高保真还原和完整资源保存:
系统由三部分组成,形成一个高效的闭环:
MutationObserver 监听动态变化,若页面内容发生显著改变(如无限滚动加载),自动提交更新。只需简单的几步,即可搭建属于你的个人互联网档案馆。
确保已安装:
createdb -U postgres wayback
psql -U postgres wayback < server/init_db.sql
cd server
cp .env.example .env # 编辑配置(如数据库密码、存储路径)
go build -o wayback-server ./cmd/server
./wayback-server
服务器默认运行在 http://localhost:8080。如需代理下载资源,可设置 http_proxy 环境变量。
cd browser
npm install
npm run build
browser/dist/wayback.user.js 的内容粘贴进去并保存。现在,正常浏览网页即可!页面加载完成后会自动静默归档。访问 http://localhost:8080 查看你的“互联网记忆”。
| 功能 | 描述 |
|---|---|
| 高保真还原 | CSSOM 序列化,内联样式,冻结动态行为 |
| 完整资源本地化 | HTML/CSS/JS/图片/字体全部下载并重写路径 |
| 跨域资源代理 | 服务器端解决 CORS 问题,确保资源不丢失 |
| 智能去重 | 会话级 + 服务器级双重去重,节省存储空间 |
| 版本时间线 | 可视化展示同一 URL 的历史快照,支持前后对比 |
| 全文搜索 | 基于页面内容、URL、标题的快速检索 |
| RESTful API | 提供完整的归档、查询、导出接口,方便集成 AI 工具 |
| Markdown 导出 | API 支持直接获取页面内容的 Markdown 格式,便于 LLM 处理 |













