
CanIRun.ai
CanIRun.ai 是一个完全在浏览器端运行的免费工具,无需安装任何软件,无需上传任何数据,即可精准告诉你:你的机器到底能跑哪些 AI 模型,以及跑得有多快。
在网页抓取(Web Scraping)和自动化领域,开发者常常面临两难困境:在真实网站上测试代码可能触发反爬机制、导致 IP 被封,甚至引发法律纠纷;而在本地静态 HTML 中测试,又无法模拟真实的动态渲染、JavaScript 执行和网络延迟。
Scraping Sandbox 是一个完全开源的网页抓取沙盒平台,旨在为开发者、数据工程师和自动化构建者提供一个安全、基于浏览器的真实环境,用于构建、测试和运行抓取智能体(Scraping Agents)。
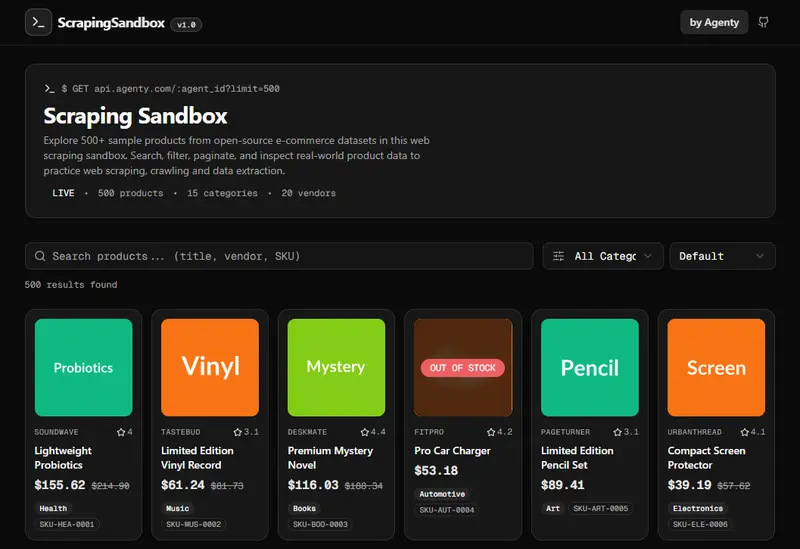
Scraping Sandbox 不仅仅是一个演示网站,它是一个功能完备的练习靶场。您可以自由地对其进行抓取,无需担心版权声明、服务条款限制或页面被删除的风险。
它专为以下场景设计:
为了最大程度地模拟真实生产环境并培养开发者的负责任抓取习惯,Scraping Sandbox 并非毫无限制。它引入了真实的速率限制机制:
⚠️ 注意:如果您超过限制,请求将被暂时阻止。请像对待生产环境一样,精心设计您的抓取工具以遵守此限制。
Scraping Sandbox 采用了一套现代化的前端与 Serverless 技术栈,确保了高性能和易扩展性:
作为一个开源项目,您可以轻松地将 Scraping Sandbox 部署到本地环境,进行离线测试或二次开发。
git clone https://github.com/Agenty/scrapingsandbox.git
cd scrapingsandbox
npm install
npm run dev
启动后,您即可在本地访问该沙盒环境,开始您的抓取实验之旅。













