
大模型显存与性能计算器
LLM 显存与性能计算器 是一款实用工具,能够帮助用户快速评估不同大语言模型的显存需求和推理性能。无论你是研究人员还是开发者,都可以利用这一工具优化模型部署方案,确保在有限硬件资源下实现最佳性能。
LittleCrawler(小爬虫)是一个基于 Python 3.11+ 和 async/await 异步编程模型 的开源爬虫框架,专注于高效、稳定地抓取主流中文社交平台的公开内容。
如果你需要批量获取小红书笔记、知乎文章或闲鱼商品的公开信息,但又不想重复造轮子,LittleCrawler(小爬虫)可能正是你需要的工具。
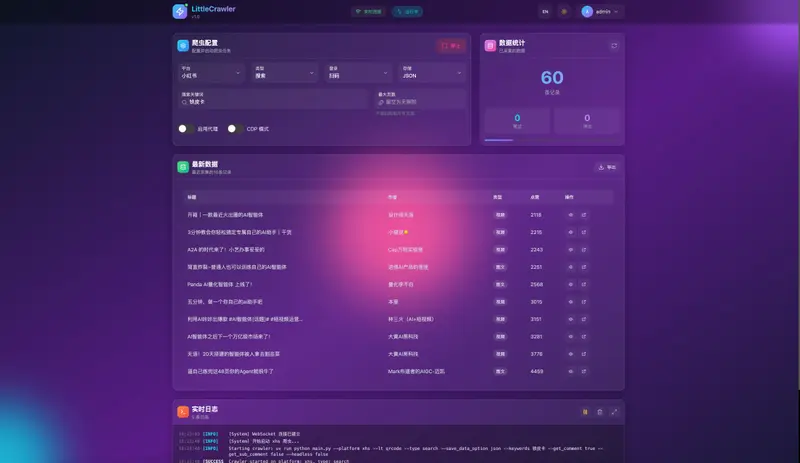
这是一个基于 Python 3.11+ 和 async/await 异步编程模型 的开源爬虫框架,专注于高效、稳定地抓取主流中文社交平台的公开内容。目前支持:
| 平台 | 代号 | 可抓取内容 |
|---|---|---|
| 小红书 | xhs | 笔记列表、笔记详情、作者信息 |
| 闲鱼 | xy | 商品信息、关联笔记、卖家资料 |
| 知乎 | zhihu | 文章列表、文章详情、作者主页 |
注:项目仅抓取公开可访问的数据,不涉及账号登录、私信或反爬绕过等敏感操作。
传统爬虫逐个请求,效率受限于网络 I/O。而 LittleCrawler 基于 asyncio + httpx + Playwright,利用异步并发能力,在单机上即可实现高吞吐抓取——尤其适合需要批量采集多个页面的场景。
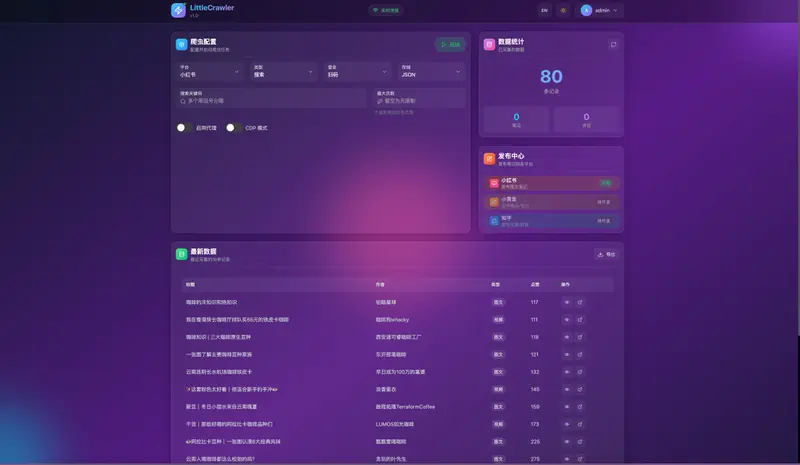
同时,它使用 Playwright 控制 Chromium,能正确渲染动态加载内容(如小红书的瀑布流),避免因前端框架导致的数据缺失。
uv(更快的依赖管理器),也可用 pip# 克隆项目
git clone https://github.com/pbeenig/LittleCrawler.git
cd LittleCrawler
# 安装依赖
uv sync
# 或
pip install -r requirements.txt
# 安装浏览器
playwright install chromium
默认使用 config/base_config.py 中的配置:
python main.py
也可指定平台和任务类型:
# 抓取小红书搜索结果
python main.py --platform xhs --type search
# 初始化 SQLite 数据库
python main.py --init-db sqlite
所有抓取结果会自动存入本地数据库,便于后续分析或导出。
项目提供了一个轻量级 Web 管理界面,方便查看任务状态与数据。
# 1. 编译前端
cd ./web && npm run build
# 2. 启动后端 API + 静态文件服务
uv run uvicorn api.main:app --port 8080 --reload
访问 http://127.0.0.1:8080 即可使用。
# 启动纯 API 服务
API_ONLY=1 uv run uvicorn api.main:app --port 8080 --reload
# 在另一个终端启动前端开发服务器
cd ./web && npm run dev
前端默认代理到 8080 端口,支持热重载,适合二次开发。
⚠️ 注意:请遵守各平台《robots.txt》及服务条款,合理控制请求频率,避免对目标服务器造成压力。













