无需下载软件,不用上传照片,打开浏览器即可生成符合打印标准的身份证复印件。LocalScan证件盾,专为解决日常证件提交场景中的效率、精度与隐私三大痛点而设计。

所有处理在你的浏览器中完成——图像不上传,数据不离开设备。
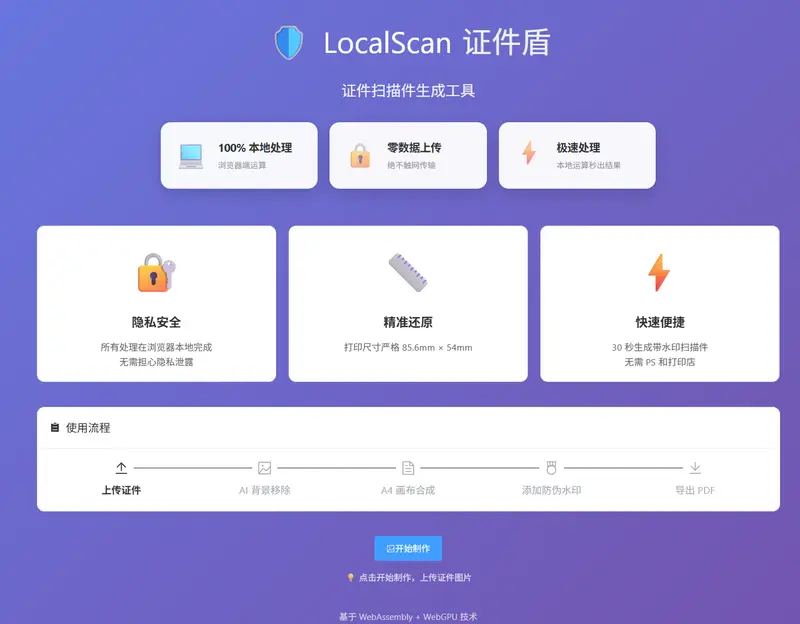
解决什么问题?
- 打印店排版收费贵,还可能留存你的证件照片
- 自己用 PS 或手机 App 裁剪,比例不准、文字模糊、打印后还得手动缩放
- 多数在线“证件扫描”工具要求上传图片,存在身份证信息泄露风险
LocalScan 证件盾从设计之初就坚持:本地处理 + 精准输出 + 防滥用保护。
核心功能
智能图像处理(无需手动修图)
- 上传手机拍摄的身份证照片
- 自动完成:
- 边缘检测:精准识别证件四边
- 透视矫正:消除拍摄角度导致的变形
- AI 抠图:去除杂乱背景
- 画质增强:提升文字清晰度,避免打印模糊
一键生成打印级文件
- 自动将证件等比例合成到 A4 画布
- 输出 300 DPI 高分辨率图像(符合政务/企业打印标准)
- 支持保存为 PDF 或 PNG,无需任何后期调整,直接送印
100% 本地计算,零数据上传
- 基于 WebAssembly (WASM) + WebGPU 加速
- 所有图像处理在浏览器内存中完成
- 无后端服务器,不收集、不传输、不存储任何用户数据
- 即使断网也能使用
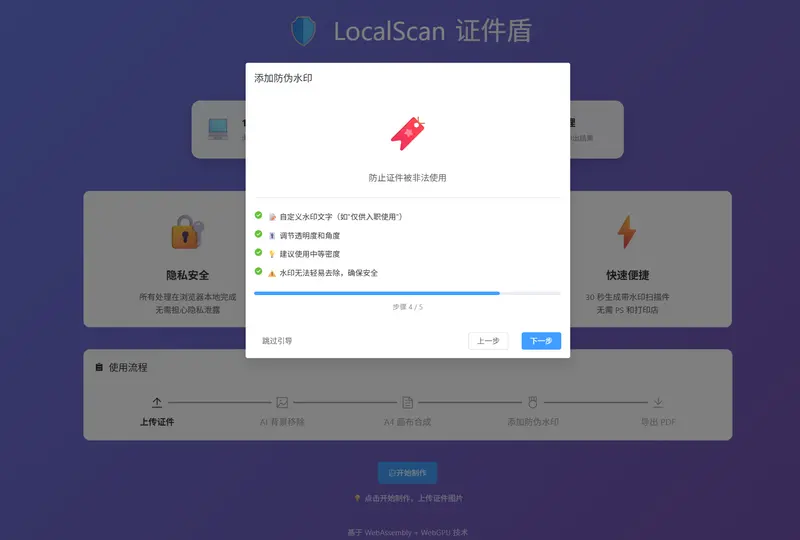
自定义防伪水印(防止信息滥用)
- 可添加文字水印,如:
- 支持调节:
- 透明度(避免遮挡关键信息)
- 旋转角度(45° 斜纹更安全)
- 密度(覆盖整个证件区域)
- 水印直接压印在证件图像上,无法轻易去除
正反面自动排版
- 分别上传身份证正面与反面
- 自动合成到同一张 A4 纸:
- 上半部分:正面(正向)
- 下半部分:反面(180° 反向,符合复印习惯)
- 一步生成,告别手动拼图
适用场景
- 求职者:快速生成入职所需身份证复印件
- 学生:办理学籍、考试、校园卡等手续
- 居民:社保、户籍、公积金等政务服务
- HR/行政人员:批量处理员工证件(多人使用同一台电脑即可)
- 自由职业者/小微创业者:提交资质文件、合同附件等
只需一个现代浏览器(Chrome / Edge / Safari 最新版),无需安装任何软件。
技术实现
- 前端框架:纯 Web 技术,无后端依赖
- AI 模型:基于 TensorFlow.js 的轻量级边缘检测与抠图模型
- 性能优化:关键图像处理通过 WASM 编译加速,确保在手机浏览器上也能流畅运行
- 输出标准:严格遵循 A4 尺寸(210×297mm)与 300 DPI 打印规范
因为没有服务器,所以你看到的每一像素,都只存在于你的设备中。
隐私承诺
- 不请求摄像头权限(仅需文件上传)
- 不使用 Cookie 跟踪
- 不嵌入任何第三方分析脚本(如 Google Analytics)
- 源码结构透明,可自行审查(计划后续开源核心模块)