
飞书 aily
飞书aily 是飞书旗下智能体平台,只需对话即可快速创建专属智能体。通过MCP 协议连接企业知识与业务系统,内置丰富工具与服务市场,让智能体真正懂业务。
LatentMAS 是一种多智能体推理框架,将智能体协作从 token 空间转移到模型的潜在空间(latent space)。 智能体不再产生长篇文本推理痕迹,而是通过各自的工作记忆传递潜在思想(latent thoughts)进行通信。
普林斯顿大学、伊利诺伊大学厄巴纳-香槟分校与斯坦福大学的研究者近日联合提出一个全新的多智能体推理框架——LatentMAS(Latent Multi-Agent System)。该框架突破了传统多智能体系统依赖自然语言文本交互的限制,首次将协作过程从 token 空间迁移到模型的潜在空间(latent space),显著提升了推理效率与性能。

在当前主流的基于大语言模型(LLM)的多智能体系统中,智能体之间的协作通常通过生成和解析自然语言完成。例如,一个智能体输出一段解释性的文字,另一个智能体再阅读这段文字继续推理。这种方式看似直观,实则存在明显问题:
LatentMAS 的核心思路正是规避这些瓶颈:智能体不再“说人话”交流,而是直接在模型内部的潜在表示层面传递“思想”。
LatentMAS 的关键技术在于利用模型隐藏层的嵌入(hidden embeddings)作为通信媒介,而非输出 token。其工作流程包含以下关键机制:
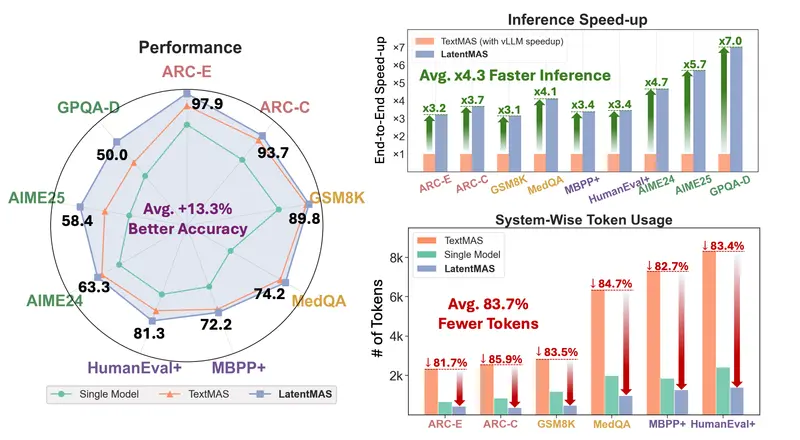
研究团队在多个代表性基准上对 LatentMAS 进行了评估,结果如下:
| 指标 | 提升效果 |
|---|---|
| 准确率 | 相比单模型提升 14.6%,相比文本式多智能体提升 2.8%(涵盖数学、科学、代码、常识任务) |
| 推理速度 | 端到端耗时降低 4×–4.3× |
| Token 消耗 | 系统级 token 使用量减少 70.8%–83.7% |
这意味着:在保持甚至提升任务质量的同时,LatentMAS 大幅降低了计算成本与延迟。
LatentMAS 具备高度通用性,适用于多种多智能体拓扑结构,包括顺序式、层次式或混合协作模式。典型应用场景包括:













