AI Autocomplete
前Meta员工创办的生产力初创公司Hero,今日宣布推出一款AI提示自动完成SDK,旨在通过上下文感知的自动填充功能,帮用户简化提示编写流程,同时为企业节省运营成本。
Memobase 是一个面向用户的结构化记忆数据库,它帮助 AI 持续积累关于用户的事实、偏好和行为轨迹,形成动态演进的用户档案。
你是否希望你的 AI 应用——无论是个性化助手、教育工具,还是虚拟伴侣——能在用户再次出现时,立刻认出他,并记得他曾说过什么、做过什么?
现在,这个能力不再需要从零构建。Memobase,一个专为生成式 AI(GenAI)打造的长期用户记忆系统,正在让这件事变得简单而可靠。
Memobase 是一个面向用户的结构化记忆数据库,它帮助 AI 持续积累关于用户的事实、偏好和行为轨迹,形成动态演进的用户档案。
它的核心目标很明确:
让 AI 不只是“这次聊得好”,而是“每次都知道你是谁”。
接入后,AI 能自动识别对话中有价值的信息——比如“我叫 Bob”“我对咖啡过敏”“我喜欢科幻电影”——并将其持久化存储。下一次对话时,这些信息将被智能召回,融入上下文,实现真正意义上的个性化交互。
这就像给 AI 安装了一个“记忆中枢”,无需你手动编写规则或维护数据库逻辑。
目前大多数 GenAI 应用依赖以下几种方式处理记忆:
而 Memobase 的出现,正是为了填补这一空白:它不是代理的记忆,而是用户本身的记忆系统。
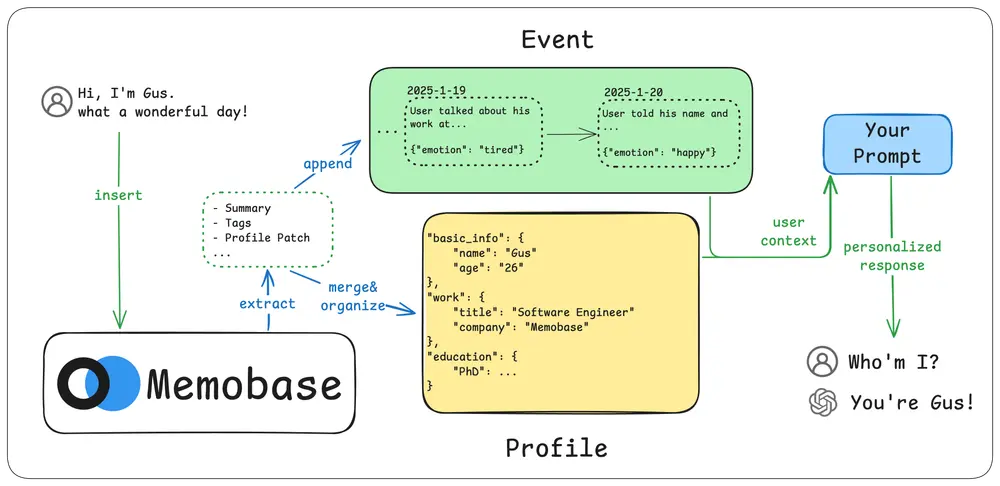
所有记忆围绕“用户”组织,而非会话或机器人。你可以精确定义哪些信息值得保留,例如姓名、职业、兴趣、习惯等,确保数据服务于产品体验。
Memobase 不仅记录“说了什么”,还记录“什么时候说的”。
通过事件时间线机制,AI 可以回答诸如:
这种对时间维度的支持,在同类系统中处于领先水平。
并非所有对话内容都应成为永久记忆。Memobase 提供灵活配置策略,支持:
每次对话结束后,Memobase 会在后台异步分析整段聊天记录,批量生成记忆条目。这种方式不仅降低实时调用开销,也显著减少嵌入(embedding)API 的使用频率。
近期更新中,插入成本已降低 30%(v0.0.38),更适合大规模部署。
支持多种接入方式:
只需几行代码,即可将现有 LLM 流程接入 Memobase。
在基于 900 场真实对话的测试中,Memobase 在记忆准确率、召回效率和时间推理能力上均优于主流开源方案,包括 mem0、langmem 和 zep。
最新版本(v0.0.37)重新运行了 LOCOMO 基准测试,综合指标达到当前最优水平(SOTA)。
此外,细粒度事件摘要功能已上线,支持按关键词、时间段精确搜索用户历史行为。
Memobase 基于成熟技术栈构建,具备高可用与可观测性:
无论你是本地部署还是云端使用,都能快速启动并稳定运行。