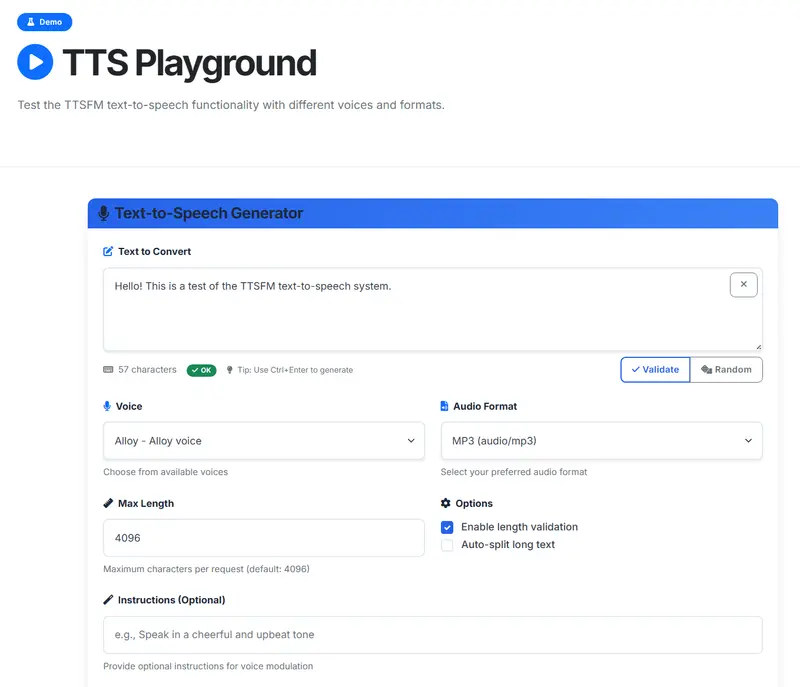
如果你正在寻找一个无需API密钥、完全免费、兼容OpenAI接口的文本转语音解决方案,那么 TTSFM 可能正是你所需要的工具。

TTSFM 是一个开源的 Python 客户端,基于对 openai.fm 服务的逆向工程实现,提供了与 OpenAI TTS API 兼容的接口(如 /v1/audio/speech),可用于快速生成高质量语音内容。
✨ 主要功能一览
- 🆓 完全免费使用:无需注册账号或申请API密钥,即可直接调用文本转语音服务。
- 🎯 兼容OpenAI接口:支持标准 OpenAI TTS 接口,可无缝替代官方API,降低迁移成本。
- ⚡ 同步与异步支持:提供同步和异步两种Python客户端,适配不同开发场景,尤其适合高并发任务。
- 🗣️ 支持11种语音类型:包括 alloy、echo、fable、onyx、nova、shimmer 等所有主流语音风格,满足多样化的角色需求。
- 🎵 6种音频格式输出:支持 MP3、WAV、OPUS、AAC、FLAC 和 PCM 格式,灵活适配播放、存储等不同用途。
- 🐳 Docker一键部署:带网页界面的Docker镜像已准备就绪,方便快速搭建本地TTS服务。
- 🌐 网页测试界面:提供图形化操作平台,便于测试不同语音和格式配置效果。
- 🔧 命令行工具:内置CLI工具,适用于脚本化处理或自动化流程中的TTS生成。
- 📦 类型提示支持:全面的类型注解提升代码可读性和IDE自动补全体验。
- 🛡️ 完善的错误处理机制:异常层级清晰,内置重试逻辑,增强程序健壮性。
- 🔄 批量文本处理能力:支持并发请求,可一次性生成多个音频文件,提升效率。
- 📊 智能文本验证与分割:自动检测并拆分超长文本,确保语音生成质量。
🛠️ 使用场景推荐
- AI助手语音播报
- 视频配音自动生成
- 游戏NPC语音合成
- 教育/阅读类产品的内容语音化
- 快速原型开发中的TTS集成
📦 如何获取?
TTSFM 已开源,可在GitHub上获取完整源码,并支持通过 pip 安装使用。同时也提供 Docker 镜像,方便快速部署本地服务。