
kontext-make-person-real
kontext-make-person-real 是一个针对FLUX.1-Kontext-dev 的小型但高效的 LoRA,专注于提升 AI 生成人物图像的真实感。如果你在使用 SDXL 或 FLUX 时常常遇到人物面部“AI 感”过重的问题,这个 LoRA 值得一试。
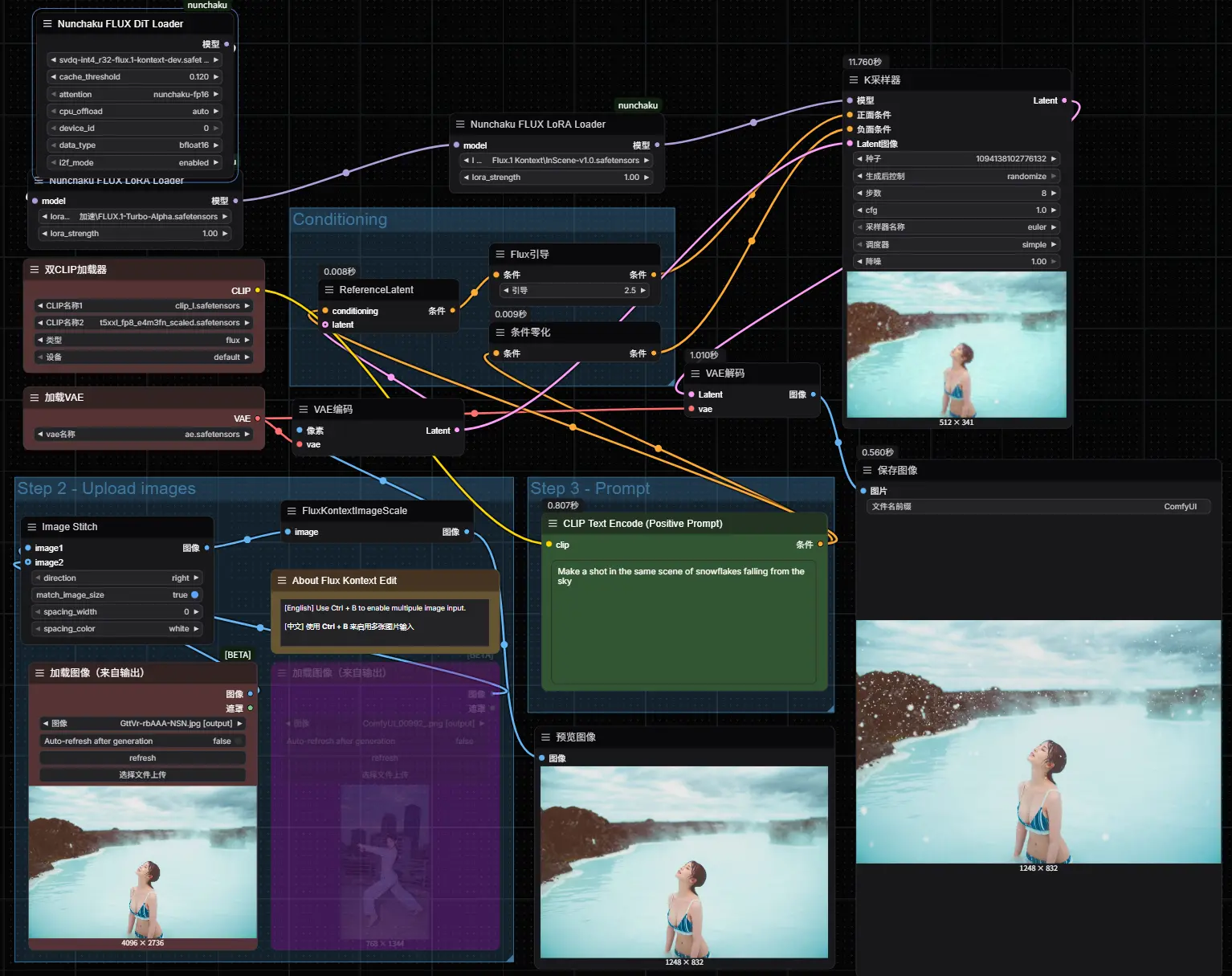
InScene 是一个为 Flux.1-Kontext.dev 设计的 LoRA,旨在生成与源图像保持场景一致性的图像。它基于 Flux.1-Kontext.dev 进行训练。主要用途是生成镜头变体,同时保持背景、整体环境、角色和风格不变。

在图像生成领域,保持场景一致性是一个重要挑战。当你希望在同一背景、风格、角色设定下生成不同镜头角度或构图的图像时,传统模型往往难以维持整体环境的一致性。
InScene 是一个为 Flux.1-Kontext.dev 设计的 LoRA 模型,专为解决这一问题而生。它能够基于原始图像生成新的变体镜头,同时保持场景、背景、角色和风格不变。
InScene 是基于 Flux.1-Kontext.dev 模型训练的 LoRA模型,专注于生成与源图像场景一致的变体图像。
它的核心目标是:
为了获得最佳效果,请按照以下方式构造提示词(prompt):
提示词应以“Make a shot in the same scene of(在同一场景中拍摄)”开头,然后描述你希望生成的新图像内容。
示例:
通过这种方式,模型能更好地理解你希望在不改变整体场景的前提下生成什么样的图像变体。
模型擅长:
典型应用场景:
尽管 InScene 在保持场景一致性方面表现出色,但仍存在一些限制:
InScene 的 LoRA 模块基于 Flux.1-Kontext.dev 主模型进行微调,训练数据来源于 WebVid 数据集。
具体训练方式如下:
训练目标是让模型学会在不改变场景本质的前提下,生成新的镜头视角或构图变化。














