
阿里云旗下的通义团队发布了最新的实验性推理模型——QwQ-32B-Preview。这款模型正处于预览阶段,尽管在某些方面仍面临挑战,但其性能已经达到了与现有模型o1-mini相当的水平,特别是在数学能力上,更是超越了o1-preview。下面我们将深入了解QwQ-32B-Preview的特点、局限性及其在技术领域的表现。
- 官方介绍:https://qwenlm.github.io/zh/blog/qwq-32b-preview
- 模型:https://modelscope.cn/organization/qwen
- Demo:https://huggingface.co/spaces/Qwen/QwQ-32B-preview

模型特点与局限性
特点- 增强的AI推理能力:QwQ-32B-Preview是通义团队在提高人工智能推理能力方面的一次重要尝试,旨在让机器更好地理解和解决复杂问题。
- 数学与编程的突出表现:模型在数学和编程领域展现出了显著的优势,能够处理复杂的计算任务和编程挑战。
- 语言混用问题:模型在回答问题时可能出现语言混用的情况,影响信息传递的清晰度和准确性。
- 推理循环:面对复杂的逻辑问题,模型有时会陷入重复的推理循环中,导致答案冗长且偏离主题。
- 安全性考量:尽管模型已经实施了基本的安全措施,但仍然存在产生不当或带有偏见的内容的风险,且容易受到对抗性攻击的影响。建议在生产环境中谨慎部署。
- 领域间能力差异:虽然在数学和编程方面表现出色,但QwQ-32B-Preview在其他领域的能力还有待提升,性能会随着任务的复杂性和专业性而变化。
技术领域的表现
为了评估QwQ-32B-Preview的实际能力,研发团队进行了多项测试,涵盖了数学、科学和编程等多个方面。以下是几个关键评测集的表现数据:- GPQA(研究生水平科学推理):得分65.2%,显示出模型具备较高的科学问题解决能力。
- AIME(中学数学竞赛):达到50.0%的准确率,表明模型拥有强大的数学问题解决技巧。
- MATH-500(全面数学评测):取得了90.6%的高分,证明了其在广泛数学主题上的深厚理解。
- LiveCodeBench(编程能力评估):同样获得了50.0%的成绩,反映出模型在实际编程环境中的良好适应能力。
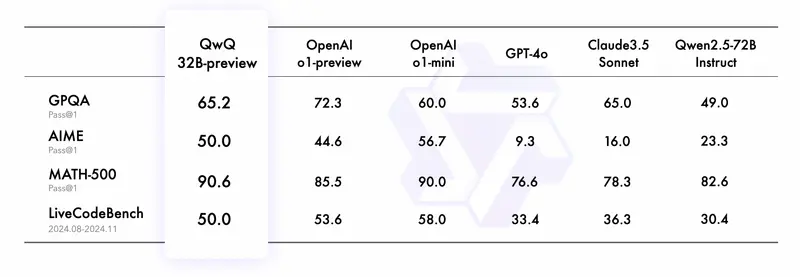 这些评测结果不仅展示了QwQ-32B-Preview在特定技术领域的强大实力,也为未来的改进方向提供了宝贵的参考。
这些评测结果不仅展示了QwQ-32B-Preview在特定技术领域的强大实力,也为未来的改进方向提供了宝贵的参考。
评论0