

新型SD模型压缩方法VQDM:通过向量量化技术,能够将大型的文本到图像扩散模型压缩到较低比特位表示,同时保持图像生成的高质量
Yandex 研究、HSE 大学、Skoltech、MIPT、Neural Magic和IST 奥地利的研究人员推出...


新型视频深度估计方法DepthCrafter:为开放世界(即不受限制、多样化的现实世界场景)的视频生成时间上连贯、细节丰富的深度序列
腾讯人工智能实验室、香港科技大学和腾讯 PCG ARC 实验室的研究人员推出新型视频深...
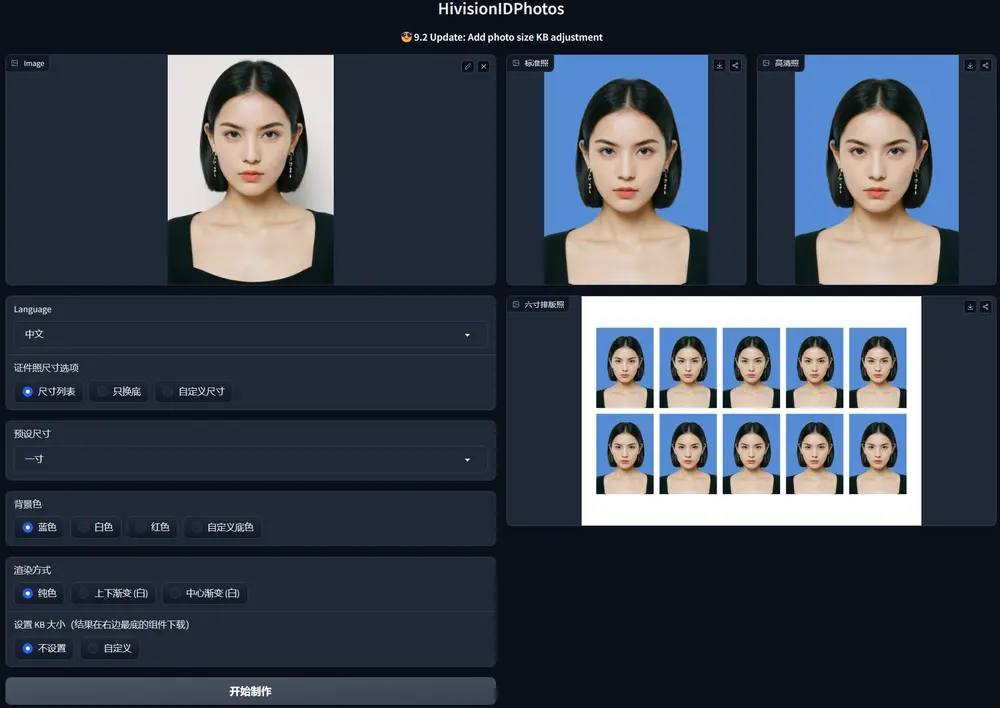
AI证件照制作框架HivisionIDPhoto:对多种用户拍照场景的识别、抠图与证件照生成
HivisionIDPhoto是一个轻量级的AI证件照制作算法,提供了一个实用且智能的身份证照...
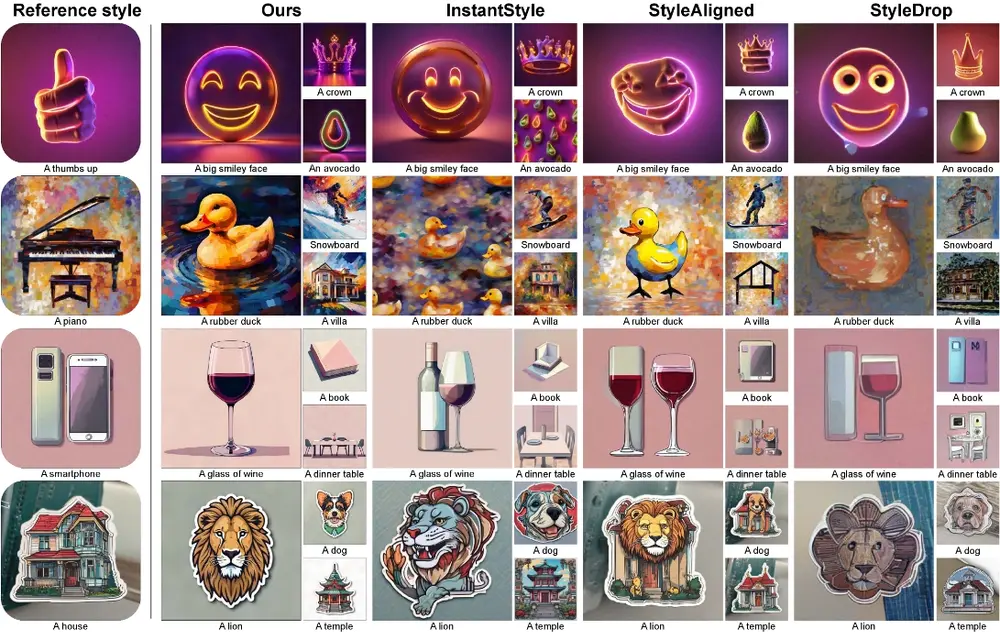

VectorJourney| Pretend to Travel:卡通插画与真实结合的FLUX LoRA模型
VectorJourney| Pretend to Travel是由Muertu基于FLUX.1-dev上训练的LoRA模型,巧...

AWPortrait-FL:基于FLUX.1-dev 的人物微调FLUX模型
AWPortrait-FL是由DynamicWang在FLUX.1-dev 基础上微调的FLUX模型,其不仅使用了 A...

适用于 DiTs 模型的快速后训练向量量化方法 VQ4DiT:能够在各种资源受限的环境中高效运行,同时保持生成图像的质量。
浙江大学和vivo的研究人员推出一种适用于 DiTs 的快速后训练向量量化方法 VQ4DiT,...



Luma AI推出AI视频生成服务Dream Machine,通过自然语言描述生成逼真的视频
今年初,OpenAI 推出的生成式 AI 视频技术 Sora 震撼了市场,但其服务并未对大众开...