
VoiceFlow - 最新版
VoiceFlow是一款本地运行的 Whisper 语音转文字工具,免费、离线、无账户,将 OpenAI 的 Whisper 语音识别能力直接部署到您的 Windows 电脑上。

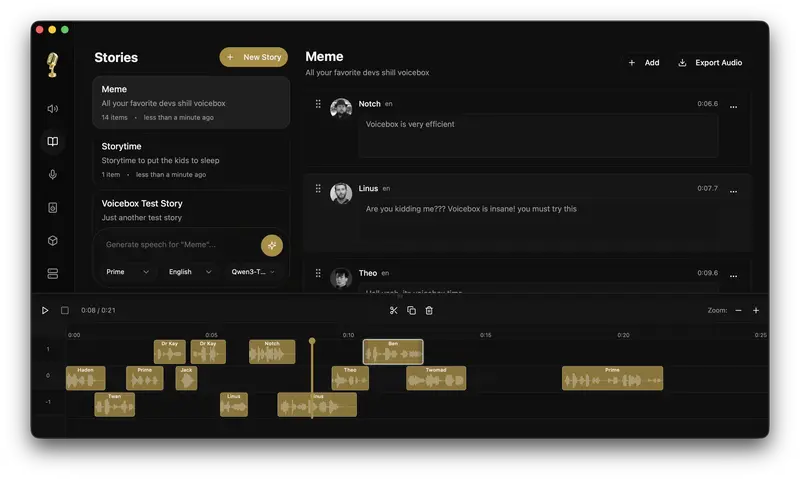
Voicebox 是一个本地优先的语音克隆工作室,具备类似数字音频工作站的功能,专为专业语音合成设计。您可以将其视为 ElevenLabs 的本地、免费且开源的替代方案 —— 下载模型、克隆声音,并在您的机器上完全本地生成语音。
299MB0 人已下载 手机查看
![Voicebox的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2026/02/1770455507-1770455507-Voicebox-2.webp)
Voicebox是一款本地优先的专业语音克隆与合成工作室,具备数字音频工作站级别的编辑能力,专为高质量语音合成场景设计。它可以看作是ElevenLabs的本地、免费、开源替代方案——无需依赖云端服务,下载对应语音模型后,就能在个人电脑上完成声音克隆、语音生成、多轨音频编辑全流程操作,所有数据与模型均留存本地,兼顾隐私与灵活性。
与主流云端语音服务相比,Voicebox彻底打破订阅制与数据锁定的限制,核心优势集中在五大维度:
无需安装Python环境,无需依赖云端算力,没有生成次数与时长限制,下载即用——无论是个人内容创作,还是开发者构建语音驱动应用,Voicebox都能提供一站式本地语音解决方案。
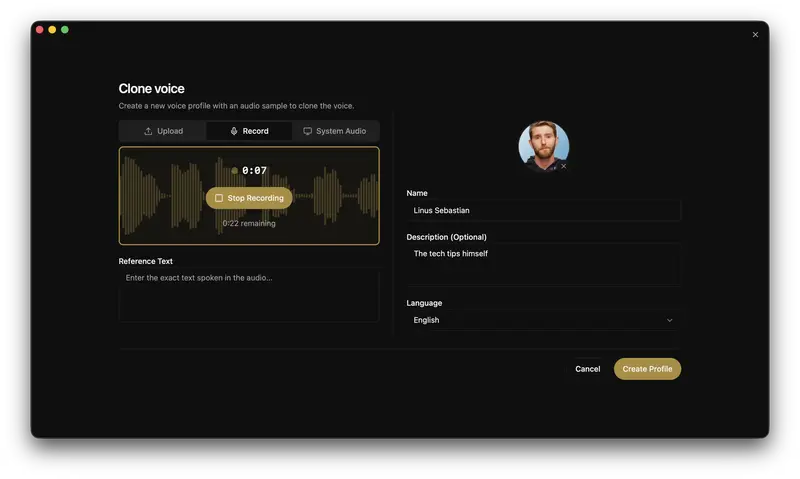
Voicebox依托阿里巴巴开源的Qwen3-TTS模型,实现行业领先的零样本语音克隆能力,仅需几秒音频样本,就能复刻出近乎完美的目标声音,核心特性:
针对克隆后的声音,提供完善的配置文件管理能力,方便用户批量管理、复用与共享:
基于克隆声音或内置音色,提供灵活的文本转语音功能,适配不同创作场景:
内置专业级时间线故事编辑器,专为多语音叙述、播客、对话场景设计,是普通TTS工具不具备的核心能力:
兼顾语音采集与文本转换需求,实现“录制-转录-编辑”闭环:
所有生成操作均留痕,方便用户回溯、复用与修改:
适配不同算力与使用场景,提供三种部署方案:
Voicebox提供完整的REST API,开发者可将语音合成、克隆、管理能力无缝集成到自有应用中,无需从零开发。以下为核心接口示例:
# 文本转语音生成
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "profile_id": "abc123", "language": "en"}'
# 列出所有语音配置文件
curl http://localhost:8000/profiles
# 创建新的语音配置文件
curl -X POST http://localhost:8000/profiles \
-H "Content-Type: application/json" \
-d '{"name": "My Voice", "language": "en"}'
应用启动后,完整的API文档可通过http://localhost:8000/docs访问,包含所有接口的参数说明、返回格式与调用示例,降低集成成本。
Voicebox采用前后端分离架构,兼顾桌面应用的原生性能与Web端的灵活性,核心技术栈如下:
| 技术层级 | 核心技术 | 核心优势 |
|---|---|---|
| 桌面应用框架 | Tauri (Rust) | 打包体积小10倍,原生性能,低内存占用,跨平台兼容 |
| 前端界面 | React + TypeScript + Tailwind CSS | 类型安全,界面流畅,样式可定制化程度高 |
| 状态管理 | Zustand + React Query | 轻量高效,支持异步状态管理,优化数据请求与缓存 |
| 后端服务 | FastAPI (Python) | 异步高性能,自动生成OpenAPI文档,接口开发效率高 |
| 语音核心模型 | Qwen3-TTS (PyTorch/MLX) | 阿里开源,高保真克隆,多语言支持,推理速度快 |
| 语音转录 | Whisper (PyTorch/MLX) | 开源通用转录模型,多语种高准确率 |
| 推理引擎 | MLX (Apple Silicon) / PyTorch (全平台) | MLX适配Apple Silicon极致加速,PyTorch保障跨平台兼容 |
| 本地存储 | SQLite | 轻量嵌入式数据库,无需额外部署,数据本地留存 |
| 音频处理 | WaveSurfer.js + librosa | 前端波形可视化,后端专业音频处理,兼顾编辑与分析 |
Voicebox目前已实现核心语音克隆、合成与编辑能力,未来将持续迭代,目标打造覆盖全场景的一站式语音处理平台。
| 功能 | 核心描述 |
|---|---|
| 实时流式合成 | 生成过程中逐词流式输出音频,无需等待完整生成,适配实时交互场景 |
| 多角色对话模式 | 支持多说话者自动轮换,一键生成自然对话音频,简化剧本配音 |
| 专业语音效果 | 新增音高变换、混响、变声等效果,支持M3GAN风格等创意音效处理 |
| 词级精度时间线 | 升级编辑器,支持词级音频分割与编辑,精准调整语音节奏与停顿 |
| 多模型兼容 | 陆续接入XTTS、Bark等主流开源语音模型,用户可按需切换 |














