
FocusFlow - 最新版
FocusFlow是一款为 Windows 打造的专注计时器,它会自动让路,不碍您事。开始一个时段,最小化至浮动悬浮窗,然后只管专心工作。追踪您的时长。达成您的目标。

MTranServer是一个超低资源消耗速度超快的离线翻译模型服务器,无需显卡。单个请求平均响应时间 50 毫秒。支持全世界主要语言的翻译。
116MB0 人已下载 手机查看
![MTranServer的使用截图[1]](https://pic.sd114.wiki/wp-content/uploads/2026/01/1767424424-1767424424-MTranServer-3.webp)
如果你需要一个完全离线、响应极快、资源占用极低的本地翻译服务,MTranServer 正是你在找的工具。
它是一个轻量级翻译模型服务器,单请求平均响应时间仅 50 毫秒,运行时几乎不占用内存,无需独立显卡,在普通笔记本甚至树莓派上都能流畅运行。支持全球主要语言互译,启动后即可通过 HTTP 接口提供翻译服务。
更重要的是:它是完全本地运行的,不依赖任何云端 API,因此可以实现“无限免费翻译”——只要你愿意接受略低于大模型的翻译质量。
注意:MTranServer 的目标不是取代 DeepL 或 Google Translate 的语言质量,而是提供一个稳定、快速、可私有部署的本地替代方案。对翻译精度要求极高的场景,仍建议使用在线大模型 API。
前往 GitHub Releases 下载对应平台的二进制文件,直接在终端运行:
./mtranserver --host 127.0.0.1 --port 8080
程序启动后,会自动输出两个地址:
首次翻译某语言对(如“中文→英文”)时,服务器会自动下载对应的小型翻译模型(约几十 MB)。这个过程需要几秒到几十秒(取决于网络),之后所有请求都将进入毫秒级响应。
建议在正式使用前,先手动发起一次翻译请求,让模型预加载完成。
若你希望完全离线运行(例如内网环境),可启动时加上 --offline 参数,但需提前手动将所需模型放入模型目录(默认 ~/.config/mtran/models)。
在任意目录创建 compose.yml:
services:
mtranserver:
image: xxnuo/mtranserver:latest
container_name: mtranserver
restart: unless-stopped
ports:
- "8989:8989"
environment:
- MT_HOST=0.0.0.0
- MT_PORT=8989
- MT_ENABLE_UI=true
volumes:
- ./models:/app/models
然后执行:
docker compose up -d
模型会持久化保存在本地 ./models 目录,升级或重启容器不会丢失。
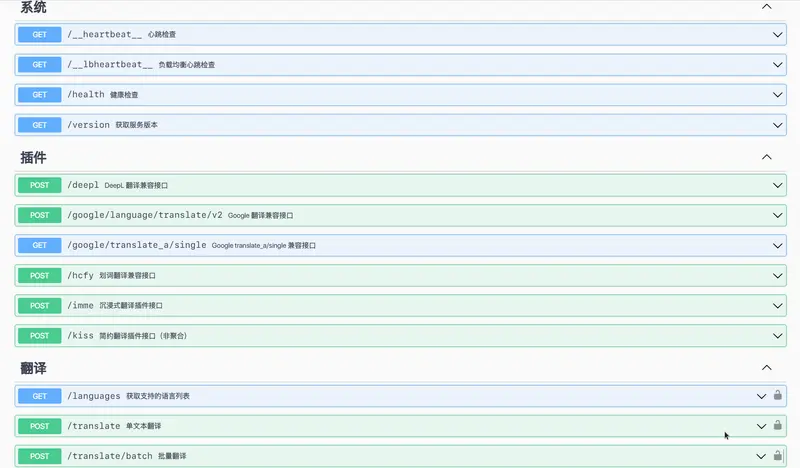
MTranServer 不仅提供标准 REST API,还原生兼容多种浏览器翻译插件的接口协议,让你无缝替换现有在线服务:
| 插件/客户端 | 兼容接口路径 | 设置方式 |
|---|---|---|
| 沉浸式翻译 | /imme | 自定义 API URL |
| 简约翻译 | /kiss | Custom 接口 |
| DeepL 客户端 | /deepl | 使用任意 Auth Key |
| Google Translate 客户端 | /google/language/translate/v2 或 /google/translate_a/single | 使用任意 API Key |
| 划词翻译 | /hcfy | 支持 token 验证 |
所有接口均支持通过
MT_API_TOKEN环境变量或 URL 参数(如?token=xxx)添加简易认证,保护本地服务不被滥用。
-version, -v 显示版本
-log-level 日志级别(debug/info/warn/error)
-config-dir 配置目录(默认 ~/.config/mtran/server)
-model-dir 模型目录(默认 ~/.config/mtran/models)
-host 监听地址(默认 0.0.0.0)
-port 端口(默认 8989)
-ui 启用 Web UI(默认开启)
-offline 禁用自动下载模型
-worker-idle-timeout Worker 空闲超时(秒,默认 300)













