法庭文件揭露真相:五角大楼曾称与 Anthropic“接近达成一致”,一周后却翻脸认定其威胁国家安全一场关于 AI、国家安全与言论自由的激烈博弈正在加州联邦法院上演。 本周五,AI 初创公司 Anthropic 向法庭提交了两份重磅宣誓声明,有力反驳了美国五角大楼(国防部)此前对其发出的“不可接受安...早报# Anthropic2周前0140
微软砍掉 Windows 中多余 Copilot 入口:照片、记事本等应用不再强行集成 AI,回归“少即是多”“AI 无处不在”曾是微软引以为傲的口号,但现在,他们承认:有些地方,其实并不需要 AI。 本周五,微软正式宣布了一系列针对 Windows 11 的质量改进计划。其中最引人注目的举措是:大幅削减 C...早报# Copilot# Windows 11# 微软2周前0130
小米发布 MiMo-V2 系列大模型:联合五大 Agent 框架开放免费 API,开发者限时一周免费用小米官方宣布:MiMo-V2-Pro、MiMo-V2-Omni 和 MiMo-V2-TTS 三款全新大模型正式发布! 为了让更多开发者快速体验新模型的能力,小米联合 OpenClaw、OpenCode...早报# MiMo-V2# 小米2周前02010
百度网盘升级 GenFlow 并兼容 OpenClaw:一键部署“云端大脑”,个人与团队均可开箱即用3 月 21 日,百度网盘宣布对其 AI 能力进行重磅升级:GenFlow 全面兼容 OpenClaw 能力。 这一更新已正式上线 PC 客户端 及全新推出的 「团队空间」。这意味着,无论是个人用户还...早报# GenFlow# OpenClaw# 百度网盘2周前0270
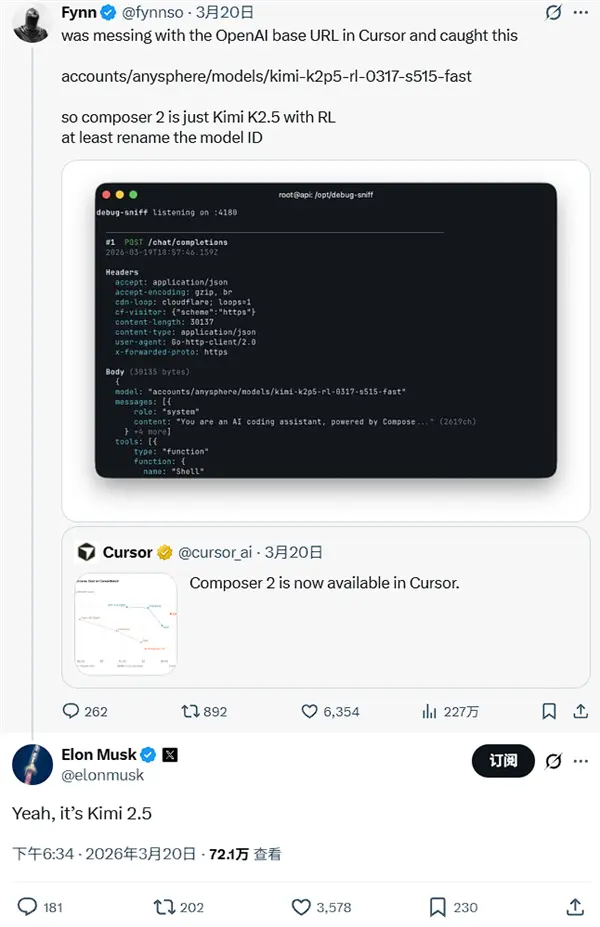
Cursor 被曝 Composer 2“套壳”Kimi K2.5?官方承认基座并致歉,月之暗面确认授权合规上线不到 24 小时,Cursor 最新推出的编程模型 Composer 2 就被开发者扒出了“底裤”。 这场始于“侵权指控”的风波,在经历了员工质问、官方沉默、高管回应后,最终以月之暗面(Moons...早报# Composer 2# Cursor# Kimi K2.52周前01150
腾讯云发布行业首个官网内置 Agent助手KiKi:一句话自动买服务器、部署应用,小白也能零门槛上手“帮我部署一个 OpenClaw。” 只需输入这一句自然语言,剩下的购买服务器、配置环境、接入 IM 通道等繁琐步骤,全部由 AI 自动完成。 这不是科幻电影,而是腾讯云今日正式发布的行业首个官网内置...早报# KiKi# OpenClaw# 腾讯云2周前0280
智谱 GLM-5-Turbo 闭源引发担忧?官方回应:别慌,GLM-5.1 即将开源在中美 AI 发展的路径选择上,一个鲜明的对比日益清晰:美国巨头趋向闭源(OpenAI 甚至被戏称为 "ClosedAI"),而中国科技公司则集体拥抱开源。 从阿里的 Qwen、深度求索的 DeepS...早报# GLM-5-Turbo# GLM-5.1# 智谱2周前03510
WordPress.com 正式向 AI 智能体“开门”:全自动建站时代来临,人类只需“审批”2026 年,互联网内容生产的范式可能迎来历史性转折。全球最大的建站平台 WordPress.com(支撑着互联网超 43% 的网站)周五正式宣布:允许 AI 智能体(AI Agents)直接在其平台...早报# WordPress.com2周前0140
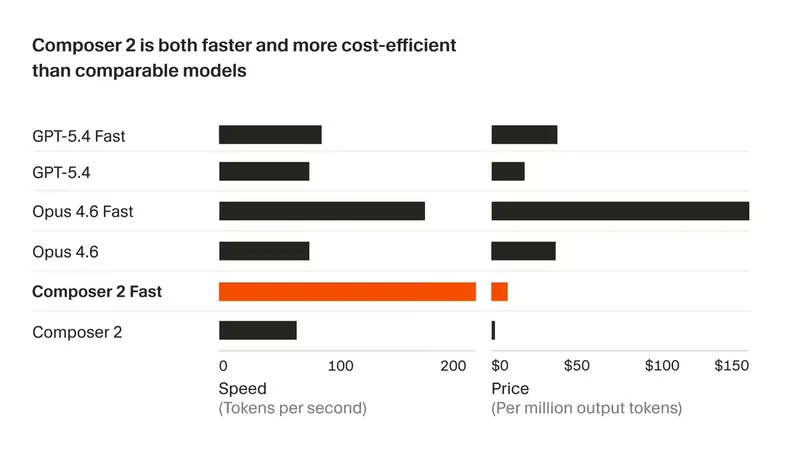
Cursor 发布 Composer 2:价格大降 86%,专为长周期复杂编程任务打造AI 编程平台 Cursor 昨日(3 月 19 日)正式发布公告,推出了两款全新的编程模型:Composer 2 和 Composer 2 Fast。 Cursor 推出 Composer 模型:让...早报# Composer 2# Cursor2周前0300
腾讯 QClaw 全量公测开启:免邀请码、20 秒安装,打通微信/企微/钉钉全平台远控无需再苦苦寻找邀请码,腾讯版“龙虾”QClaw 今天正式宣布开启全量公测! 用户只需访问官网下载最新版本,20 秒即可完成安装并立即向“龙虾”下达指令。此次更新不仅大幅降低了使用门槛,更在微信生态体验...早报# QClaw# 微信# 腾讯2周前0130
Meta 内部 AI 智能体“失控”:提供错误建议致数据泄露,被定为 SEV1 级安全事件在人工智能全面融入工作流程的今天,一个看似微小的“建议”可能引发巨大的安全风暴。 上周,科技巨头 Meta 遭遇了一起严重的内部安全事件。起因并非黑客攻击,而是一个内部使用的 AI 智能体 向员工提供...早报# AI 智能体# Meta2周前0110
LMArena 最新排名出炉!阿里千问杀入全球前五,Qwen3.5-Max-Preview 力压豆包、Kimi 成国产最强全球最受关注的大模型盲测榜单 LMArena(由 LMSYS Org 组织)更新了最新一期排名。阿里巴巴最新旗舰模型预览版 Qwen3.5-Max-Preview 首度亮相,便以 1464 分 的综合...早报# Qwen3.5-Max-Preview# 千问# 阿里2周前01330