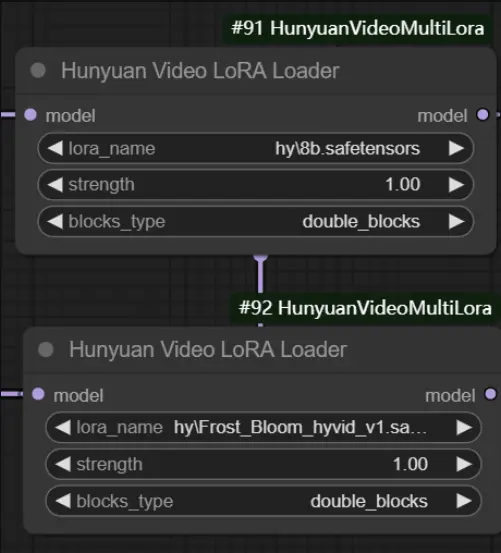
ComfyUI-HunyuanVideoMultiLora:让混元Video在加载多个LoRA时,避免模糊等污染问题ComfyUI-HunyuanVideoMultiLora是一个自定义的加载LoRA节点,让混元Video在加载多个LoRA时,避免模糊等污染问题。使用说明: 连接方式和原来没有不同,唯一注意的是多出...插件# Lora# 混元Video1年前03090
ComfyUI最新更新,增加了对蒙版和调度 LoRA 及模型权重的原生支持自12月2日以来,ComfyUI 增加了对蒙版和调度 LoRA 及模型权重的原生支持,这为用户提供了更精细的控制,使得创建复杂且定制化的图像生成流程变得更加容易。本文将详细解释如何使用这些新功能,包括...新闻# ComfyUI# Lora# 蒙版1年前05980
ComfyUI Flux Trainer:可以在ComfyUI上训练Flux模型Lora的插件ComfyUI Flux Trainer是一款可以在ComfyUI上训练Flux模型Lora的插件,此插件是以 kohya 为底层而实现的,作者建议大家的ComfyUI 是基于torch 2.4.0 ...插件# ComfyUI Flux Trainer# FLUX模型# Lora2年前06950
Multi-LoRA Composition:不经过训练直接融合多个 Lora 不损失效果来自伊利诺伊大学香槟分校和微软公司的研究人员公开了多LoRA组合来生成图像的项目。简单来说,LoRA是一种可以让文本生成图像模型更准确地呈现特定元素(如独特的字符、风格或服装)的技术。论文探讨了如何更...新技术# Lora# Multi-LoRA Composition2年前08800
一种新颖的模型微调方法DoRA:比LoRA更精细、更全面的微调策略DoRA(Weight-Decomposed Low-Rank Adaptation)是一种用于微调(fine-tuning)大型预训练模型的新方法。DoRA的核心思想是将预训练模型的权重分解为两个部...新技术# DoRA# Lora# 模型微调2年前01,3210
Stable Diffusion绘画中常用的LoRA模型是什么?在使用Stable Diffusion进行AI绘画的时候,最常用的除了大模型应该就是LoRA模型,你知道LoRA是是什么吗?你知道LoRA技术其实最初是由微软技术人员为了解决大语言模型微调而开发的吗...科普# Civitai# LiblibAI# Lora2年前08100
LoRA:为解决大语言模型微调而开发微软的研究人员于2021年推出LoRA(Low-Rank Adaptation of Large Language Models,大语言模型的低阶适应),这是为解决大语言模型微调而开发的一项技术,用于...新技术# Lora# 大语言模型# 微软2年前05990
单样本文生图模型的微调方法:解决泛化性和真实性问题来自腾讯的研究人员提出了一种面向对象的单样本文生图模型的微调方法Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with P...新技术# Lora# 微调# 文生图2年前07160