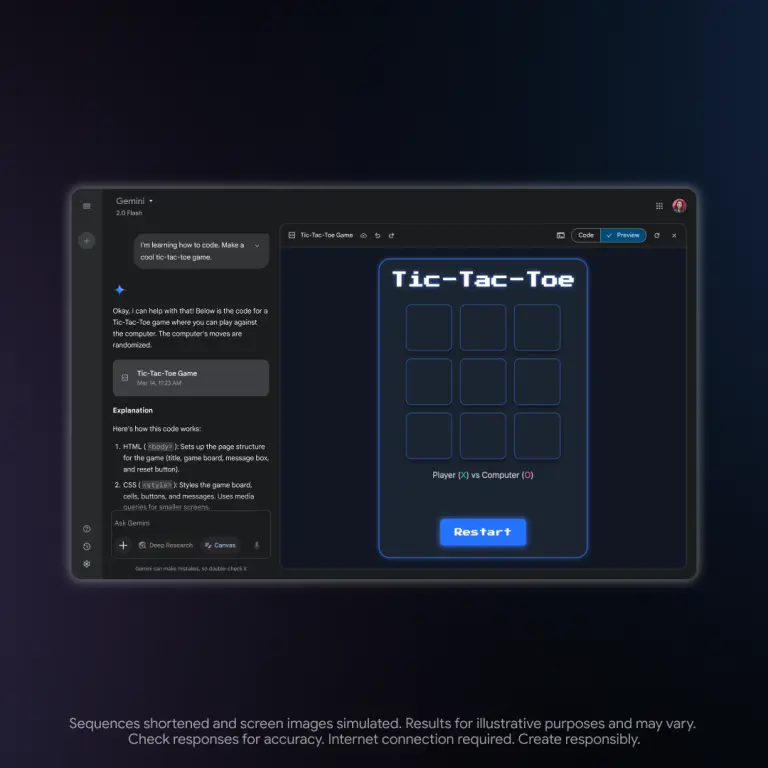
微软Copilot Search上线,挑战谷歌搜索模式,引入 AI 互动助用户延伸搜索在搜索引擎领域,AI技术正逐渐成为提升用户体验的关键。继谷歌上个月推出AI模式实验后,微软也迅速跟进,推出了Bing Copilot Search,正式向谷歌发起挑战。 谷歌的AI搜索模式 谷歌的AI...早报# Copilot Search# 微软# 谷歌1年前04000
微软Copilot Podcasts挑战谷歌NotebookLM,AI助手竞争升级在庆祝公司成立50周年之际,微软推出了一系列Copilot的新功能,进一步提升其AI助手的竞争力。其中最引人注目的新功能是Copilot Podcasts,这标志着微软正式进军生成式AI音频内容领域...早报# Copilot Podcasts# NotebookLM# 微软1年前02040
Gemini 2.5 Pro 是谷歌迄今为止最昂贵的 AI 模型谷歌最近发布了其最新的AI推理模型——Gemini 2.5 Pro,并公布了其API定价。这款模型在编码、推理和数学能力等多个基准测试中表现出色,但其定价也使其成为谷歌迄今为止最昂贵的AI模型。 Ge...早报# Gemini 2.5 Pro# 谷歌1年前02530
谷歌AI笔记工具NotebookLM 推出“自主溯源”功能,迈向主动知识构建谷歌近日为其 AI 笔记工具 NotebookLM 推出了名为“Discover”的创新功能,这一功能的上线标志着该工具从“被动接收信息”向“主动构建知识网络”的重大转变。用户现在不再需要手动上传文档...早报# AI笔记# Discover# NotebookLM1年前02350
谷歌 Gemini 2.5 Pro向免费用户开放,体验最先进的AI 模型谷歌近日宣布了一个重大消息:其最新且最先进的 Gemini模型——2.5 Pro 版,将免费向所有 Gemini 应用用户开放。此前,这一实验性模型仅限于 Gemini Advanced 订阅者使用...早报# AI 模型# Gemini 2.5 Pro# 谷歌1年前02660
谷歌发布了新推理模型Gemini 2.5系列:其特色在于回答问题前会进行“思考”过程本周二(2025年3月25日),谷歌发布了新推理模型Gemini 2.5系列,其特色在于回答问题前会进行“思考”过程。为了启动这一系列,谷歌推出了Gemini 2.5 Pro Experimental...大语言模型# Gemini 2.5# 思考模型# 推理模型1年前01980
谷歌推出 Gemini 实时 AI 视频功能,让智能助手的交互体验更加直观和便捷谷歌的 Gemini 现在已经为部分 Google One AI Premium 订阅者带来了全新的实时 AI 视频功能,让智能助手的交互体验更加直观和便捷。 Gemini Live 的新功能 屏幕读...早报# Gemini# 谷歌1年前02730
谷歌Gmail新推出的AI驱动搜索功能应能助您更快找到相关邮件谷歌宣布为Gmail推出一项新的AI驱动搜索功能,快速提供更相关的搜索结果。此次更新通过纳入近期邮件、点击量最高的邮件以及频繁联系人等因素,增强了传统的按时间顺序搜索功能。因此,用户可以更高效地找到所...早报# Gmail# 谷歌1年前02650
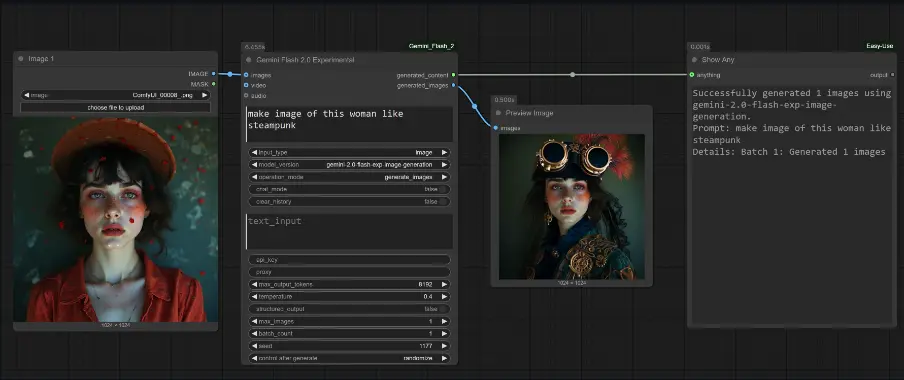
ComfyUI-Gemini_Flash_2.0_Exp:集成了谷歌的 Gemini Flash 2.0 实验模型的ComfyUI自定义节点ComfyUI-Gemini_Flash_2.0_Exp 是一个ComfyUI 自定义节点,集成了谷歌的 Gemini Flash 2.0 实验模型。它支持在 ComfyUI 工作流中直接进行文本、图...插件# ComfyUI# ComfyUI-Gemini_Flash_2.0_Exp# Gemini Flash 2.01年前07950
谷歌为 Gemini 推出“画布(Canvas)”及“音频概览(Audio Overview)”功能,提升 AI 生产力谷歌正在将其 AI 驱动的 Gemini 聊天机器人打造成一个全面的生产力工具。周二,谷歌为 Gemini 添加了两项新功能:“画布”(Canvas)和音频概览(Audio Overview),进一步...早报# Audio Overview# canvas# 画布1年前02180
谷歌推出升级Gemini 2.0模型,助力AI 搜索与助手全面进化谷歌公司于3月17日发布博文,宣布通过升级Gemini 2.0模型,推出“AI Overviews”和“AI Mode”两项全新功能,为传统搜索插上AI的翅膀。此次更新不仅提升了搜索效率,还为用户带来...早报# Gemini 2.0# 谷歌1年前02800
谷歌将高清语音模型Chirp 3引入Vertex AI平台,并计划从下周开始正式推出在生成式AI领域,文本和图像生成一直是关注焦点。然而,随着技术的快速发展,语音AI正迅速崛起,成为下一波浪潮。谷歌在这一领域的最新进展是将高清语音模型Chirp 3集成到其Vertex AI开发平台中...早报# Chirp 3# Vertex AI# 语音模型1年前02940