
新Acrobat Student Spaces
Adobe 正式推出了 Student Spaces,一款专为学生设计的免费 AI 学习工具。作为 Acrobat 生态的最新延伸,该工具将传统的 PDF 阅读体验转化为互动的学习中心,允许用户从文档、链接和笔记中一键生成演示文稿、抽认卡、测验甚至双人 AI 播客。
在数据驱动运营的今天,如何高效、稳定地获取小红书、抖音、B 站等主流平台的公开数据,是许多开发者和运营人员面临的难题。传统的爬虫方案往往深陷于复杂的 JS 逆向工程和加密参数破解中,门槛高且维护成本巨大。
MediaCrawler 是一款功能强大的多平台自媒体数据采集工具,它另辟蹊径,利用 Playwright 浏览器自动化框架 结合 登录态缓存 技术,完美避开了繁琐的逆向过程。无需破解加密算法,只需扫码登录,即可轻松抓取关键词搜索、指定帖子、二级评论及创作者主页等核心数据。
x-s, x-gorgon 等)加密极其复杂,逆向难度极大且随时可能失效。支持国内几乎所有主流自媒体平台的公开信息抓取:
核心功能矩阵:
| 功能 | 描述 | 支持状态 |
|---|---|---|
| 关键词搜索 | 根据热搜词批量抓取相关笔记/视频 | ✅ 全支持 |
| 指定帖子 ID | 精准抓取特定内容的详情与评论 | ✅ 全支持 |
| 二级评论爬取 | 深入挖掘评论区互动数据 | ✅ 全支持 |
| 创作者主页 | 批量采集大 V 或竞对的所有作品 | ✅ 全支持 |
| 登录态缓存 | 一次扫码,长期有效,避免频繁登录 | ✅ 全支持 |
| IP 代理池 | 内置代理支持,防封禁更安全 | ✅ 全支持 |
| 词云生成 | 自动分析评论情感,生成可视化词云 | ✅ 全支持 |
对于有更高需求的团队,MediaCrawlerPro 提供了全方位的进阶能力:
MediaCrawler 推荐使用现代化的 Python 包管理工具 uv,速度极快且依赖解析精准。
# 克隆项目
git clone https://github.com/NanmiCoder/MediaCrawler.git
cd MediaCrawler
# 同步 Python 环境(自动处理版本和依赖)
uv sync
# 安装浏览器驱动 (Playwright)
uv run playwright install
以抓取小红书为例:
config/base_config.py,设置关键词、爬取数量等(文件内有详细中文注释)。# 模式 A:关键词搜索爬取
uv run main.py --platform xhs --lt qrcode --type search
# 模式 B:指定帖子 ID 爬取
uv run main.py --platform xhs --lt qrcode --type detail
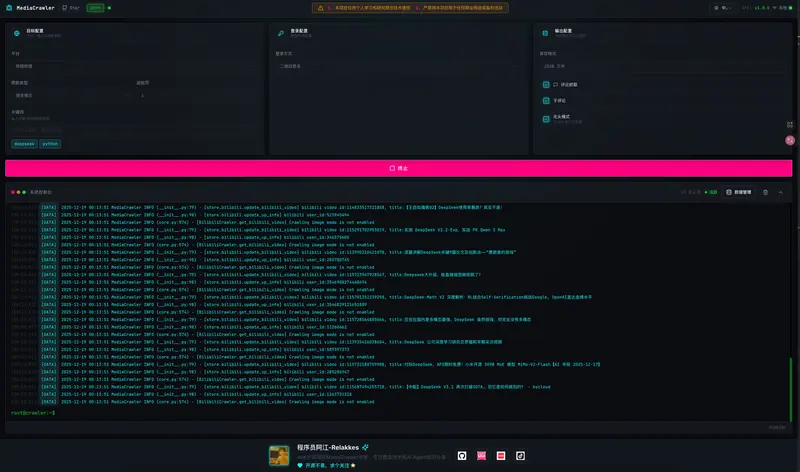
如果不喜欢命令行,MediaCrawler 还提供了友好的 Web 界面:
# 启动 API 服务
uv run uvicorn api.main:app --port 8080 --reload
访问 http://localhost:8080,即可在浏览器中可视化配置任务、实时监控日志、预览和导出数据。













