YTB2BILI
YTB2BILI是一个功能完整的 YouTube 到 Bilibili 自动化转载系统,支持从 YouTube 等平台下载视频,自动生成字幕、翻译内容、生成元数据,并定时上传到 Bilibili。
TubeTrim 是一个完全免费、开源的本地化解决方案。它利用你的本地硬件(NVIDIA GPU、Apple Silicon MPS 或 CPU),自动下载字幕并生成高质量的文字摘要。所有数据处理均在本地完成,真正实现了“数据不出域”。
“无需上传视频,无需支付 API 费用,无需担心数据泄露。TubeTrim 让你的本地硬件成为最私密的 AI 摘要引擎。”
在信息爆炸的时代,快速获取 YouTube 视频的核心内容至关重要。然而,大多数在线摘要工具不仅收费昂贵,还要求你将视频链接甚至内容数据发送到云端,存在隐私隐患。
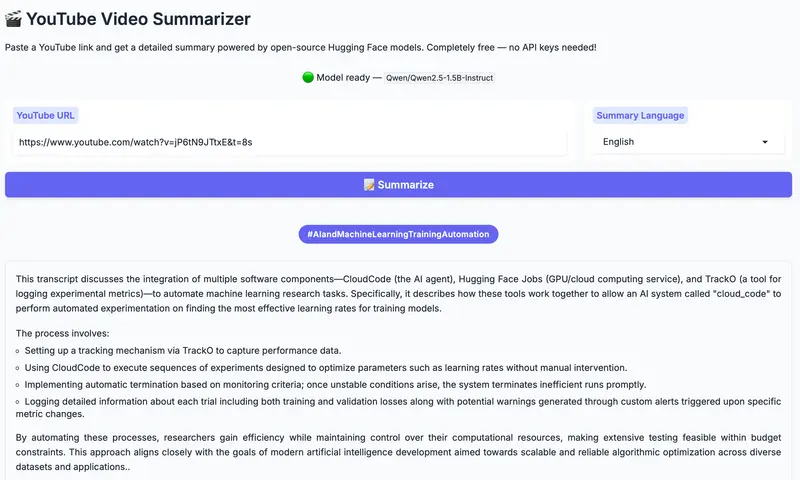
TubeTrim 是一个完全免费、开源的本地化解决方案。它利用你的本地硬件(NVIDIA GPU、Apple Silicon MPS 或 CPU),自动下载字幕并生成高质量的文字摘要。所有数据处理均在本地完成,真正实现了“数据不出域”。
TubeTrim 采用前后端分离架构,通过精心设计的流水线,在保证速度的同时最大化摘要质量。
YouTube URL
│
▼
┌─────────────────────────────────────────┐
│ Gradio Web UI (端口 7860) │
│ - 实时流式渲染 Token │
│ - 交互式标签展示 │
└───────────────────┬─────────────────────┘
│ (NDJSON Stream)
▼
┌─────────────────────────────────────────┐
│ FastAPI Backend (端口 8000) │
│ 1. 获取字幕 (youtube-transcript-api) │
│ 2. 抽取式压缩 (TF-IDF, 减少 50% 文本) │
│ 3. 智能分块 (≤4000 字符/块) │
│ 4. LLM 流式推理 (TextIteratorStreamer) │
│ 5. 正则提取 Hashtags │
└───────────────────┬─────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Hugging Face Transformers │
│ 模型: Qwen2.5-1.5B-Instruct (默认) │
│ 后端: 自动检测 (CUDA > MPS > CPU) │
└─────────────────────────────────────────┘
youtube-transcript-api 直接抓取 YouTube 自带的字幕(自动生成或手动上传),无需下载音频或进行耗时的语音转文字(STT)。TextIteratorStreamer 在后台线程逐 Token 生成,通过 NDJSON 格式实时推送到前端。用户无需等待全文生成,即可看到摘要逐字浮现。#Hashtags,并在 UI 中以彩色徽章形式展示,方便快速定位主题。TubeTrim 专为效率而生,能够智能识别并利用你现有的硬件资源:
| 硬件平台 | 加速技术 | 精度策略 | 说明 |
|---|---|---|---|
| NVIDIA GPU | CUDA | bfloat16 | 最佳性能,自动启用 Tensor Core 加速。 |
| Apple Silicon | MPS (Metal) | float16 | M1/M2/M3 芯片原生加速,含算子自动回退机制。 |
| CPU | AVX2/AVX512 | float32 | 无独显设备的标准 fallback 方案,依然可用。 |
性能优化亮点:
uv (现代 Python 包管理器)cd TubeTrim
uv sync
注:此时不会下载模型,仅安装环境。模型将在首次运行时自动缓存。
cp .env.example .env
编辑 .env 文件可自定义模型(如切换为 Qwen2.5-7B 或 32B)及生成参数。
| 变量 | 默认值 | 说明 |
|---|---|---|
HF_MODEL | Qwen/Qwen2.5-1.5B-Instruct | 可替换为任意 HuggingFace 模型 |
MODEL_TEMPERATURE | 0.2 | 低温度值确保输出专注、确定 |
API_PORT | 8000 | 后端服务端口 |
GRADIO_SERVER_PORT | 7860 | 前端界面端口 |
需要开启两个终端窗口:
终端 1:启动 API 后端
uv run yt-summarizer-api
首次运行会自动下载约 3.5GB 的模型权重至 ~/.cache/huggingface/。
终端 2:启动 Web 界面
uv run yt-summarizer-ui
浏览器访问 http://localhost:7860 即可开始使用。
TubeTrim 提供完整的 RESTful API,支持流式和非流式调用。
非流式请求:
curl -X POST http://localhost:8000/summarize \
-H "Content-Type: application/json" \
-d '{"youtube_url": "https://www.youtube.com/watch?v=VIDEO_ID", "language": "Chinese"}'
流式请求 (推荐):
curl -X POST http://localhost:8000/summarize \
-H "Content-Type: application/json" \
-d '{"youtube_url": "https://www.youtube.com/watch?v=VIDEO_ID", "language": "Chinese", "stream": true}'
响应为 NDJSON 格式,包含 status (进度), token (文本片段), hashtags (标签), error (错误) 等事件类型。