Vellum - AI 皮肤增强器
使用 OpenArt 上的高级 AI 皮肤增强器 Vellum,创建自然的肖像。它通过恢复毛孔、皱纹和自然皮肤纹理,使图像更锐利、更逼真,从而提升 AI 肖像的真实感。
在 AI 辅助科研的流程中,语言模型已能高效完成文献综述、代码生成甚至实验设计。但有一环始终依赖人工:绘制符合发表标准的学术插图。
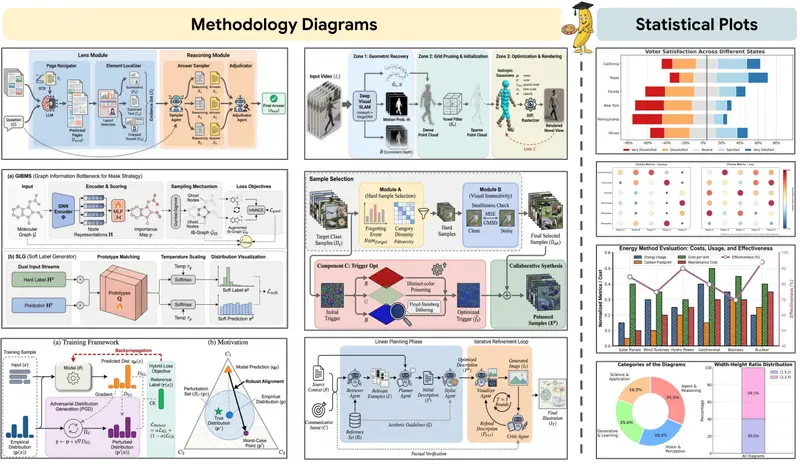
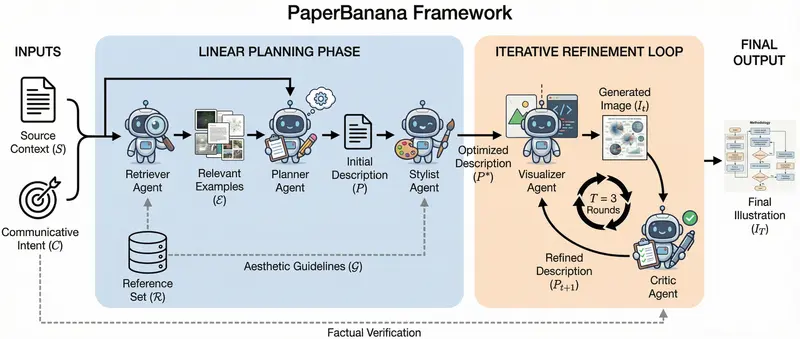
无论是模型架构图、方法流程图还是统计图表,研究者仍需花费大量时间调整布局、统一风格、校对标注。为此,北京大学与 Google Cloud AI Research 联合推出了 PaperBanana——一个专为学术插图生成设计的多智能体框架。
它不只是一个"文生图"工具,而是一套参考驱动、可迭代优化、符合学术规范的自动化工作流。
PaperBanana 将学术插图生成拆解为一条流水线,由五个专门智能体协同完成:
原始方法文本
↓
[检索智能体] → 匹配 NeurIPS 风格参考图例
↓
[规划智能体] → 生成结构化文本描述(内容+逻辑+标注)
↓
[风格智能体] → 注入学术美学规范(配色/字体/布局)
↓
[可视化智能体] → 渲染图像 或 生成可执行绘图代码
↓
[批评智能体] → 对照源文本校验,反馈修正建议
↻(最多 3 轮迭代)
↓
最终输出:publication-ready 插图 + 完整元数据
| 智能体 | 核心任务 | 关键技术 |
|---|---|---|
| 检索智能体 | 从 curated 图例库中匹配最相关参考 | 语义相似度检索 + 风格聚类 |
| 规划智能体 | 将方法描述转化为可视化所需的结构化文本 | Gemini VLM 上下文学习 + 逻辑拆解 |
| 风格智能体 | 确保输出符合学术出版美学标准 | NeurIPS 风格指南 + 视觉规则引擎 |
| 可视化智能体 | 执行渲染:图像生成 or 代码输出 | Gemini 图像模型 / Matplotlib/Plotly 代码生成 |
| 批评智能体 | 校验生成结果与源内容的一致性 | VLM 多模态比对 + 规则校验 |
💡 设计思路:将"生成"拆解为"规划→执行→校验"闭环,避免端到端黑箱模型常见的逻辑漂移与风格失准问题。
为客观评估自动化插图生成质量,研究团队构建了 PaperBananaBench——首个面向学术方法图的专用评测基准。
在 PaperBananaBench 上的系统评估显示:
| 方法 | 忠实度 | 简洁性 | 可读性 | 美观性 | 综合得分 |
|---|---|---|---|---|---|
| 直接文生图(Gemini) | 72.1 | 68.4 | 75.3 | 70.2 | 71.5 |
| Code-based 绘图代理 | 78.6 | 74.1 | 81.2 | 65.8 | 74.9 |
| PaperBanana(Ours) | 86.3 | 82.7 | 88.1 | 84.5 | 85.4 |
✅ 所有维度均显著优于单模型基线与纯代码生成方案
✅ 迭代细化机制对提升忠实度与可读性贡献最大
✅ 风格智能体有效缩小了与人工绘制图表的美学差距
PaperBanana 同样适用于折线图、热力图、箱线图等统计图表。下图即为 Nano-Banana-Pro 根据原始数据自动生成的示例:
(此处可插入示例图,实际发布时替换为真实输出)
即使图表已由人工绘制,PaperBanana 的风格智能体仍可基于 NeurIPS 指南提供优化建议:
适合:已绘制初稿、希望快速提升专业度的研究者
团队对比了两种统计图生成路径:
| 维度 | 图像生成路径 | 代码生成路径 |
|---|---|---|
| 呈现效果 | ✅ 更美观,风格统一 | ⚠️ 依赖模板,需手动调优 |
| 内容忠实度 | ⚠️ 偶发细节偏差 | ✅ 逻辑精确,可追溯 |
| 可编辑性 | ❌ 位图,修改困难 | ✅ 代码可复用、可调整 |
| 适用场景 | 示意图、概念图、汇报用图 | 实验结果图、需复现的统计图 |
💡 建议:方法架构图优先用图像生成;实验数据图推荐代码路径,兼顾准确性与可复现性。
# 方式一:PyPI 安装(推荐)
pip install paperbanana
# 方式二:源码安装(开发模式)
git clone https://github.com/llmsresearch/paperbanana.git
cd paperbanana
pip install -e ".[dev,google]"
# 推荐:交互式设置(自动打开浏览器授权)
paperbanana setup
# 或手动配置
cp .env.example .env
# 编辑 .env 文件,填入:GOOGLE_API_KEY=your-key-here
# 使用内置示例
paperbanana generate \
--input examples/sample_inputs/transformer_method.txt \
--caption "Overview of our encoder-decoder architecture with sparse routing"
# 或使用自定义方法描述
cat > my_method.txt << 'EOF'
Our framework consists of an encoder that processes input sequences
through multi-head self-attention layers, followed by a decoder that
generates output tokens auto-regressively using cross-attention to
the encoder representations. We add a novel routing mechanism that
selects relevant encoder states for each decoder step.
EOF
paperbanana generate \
--input my_method.txt \
--caption "Overview of our encoder-decoder framework"
✅ 输出路径:outputs/run_<timestamp>/final_output.png
✅ 附带内容:所有中间迭代图像、智能体决策日志、元数据 JSON
🔄 设计优势:避免"一次生成定终身",通过多轮校验逼近人工绘制质量。
| 组件 | 提供商 | 模型/版本 |
|---|---|---|
| 视觉语言模型 | Google Gemini | gemini-2.0-flash |
| 图像生成 | Google Gemini | gemini-3-pro-image-preview |
| 代码执行沙箱 | 本地 Python 环境 | Matplotlib 3.7+, Plotly 5.15+ |
from paperbanana import Generator,支持自定义智能体配置/generate-diagram --input method.txt
/generate-plot --data results.csv --type heatmap
/evaluate-diagram --image output.png --reference method.txt
| 用户类型 | 推荐用法 | 注意事项 |
|---|---|---|
| 科研学生 | 用 /generate-diagram 快速绘制方法初稿,再手动微调 | 首次使用建议从示例输入开始,熟悉输出格式 |
| 实验室 PI | 批量生成组内论文插图,统一风格规范 | 建议建立团队专属参考图例库,提升检索准确率 |
| 期刊编辑/审稿人 | 用 /evaluate-diagram 辅助检查投稿图表合规性 | 当前仅支持 NeurIPS 风格,其他会议风格待扩展 |
| AI 开发者 | 通过 Python API 集成到论文写作工具链 | 注意 API 调用频率限制,大任务建议加重试逻辑 |













