
COSE
COSE (Create Once, Sync Everywhere) 是一款专为内容创作者打造的浏览器扩展,配合 Doocs MD 编辑器使用,让你一次编辑,多平台同步发布。
你希望 PDF 的排版、代码高亮、表格样式和 GitHub 上看到的一模一样?
ghpdf 是一个无需配置、无需 LaTeX、无需模板的命令行工具,只需一行命令,即可将 .md 文件转为视觉一致的 PDF。
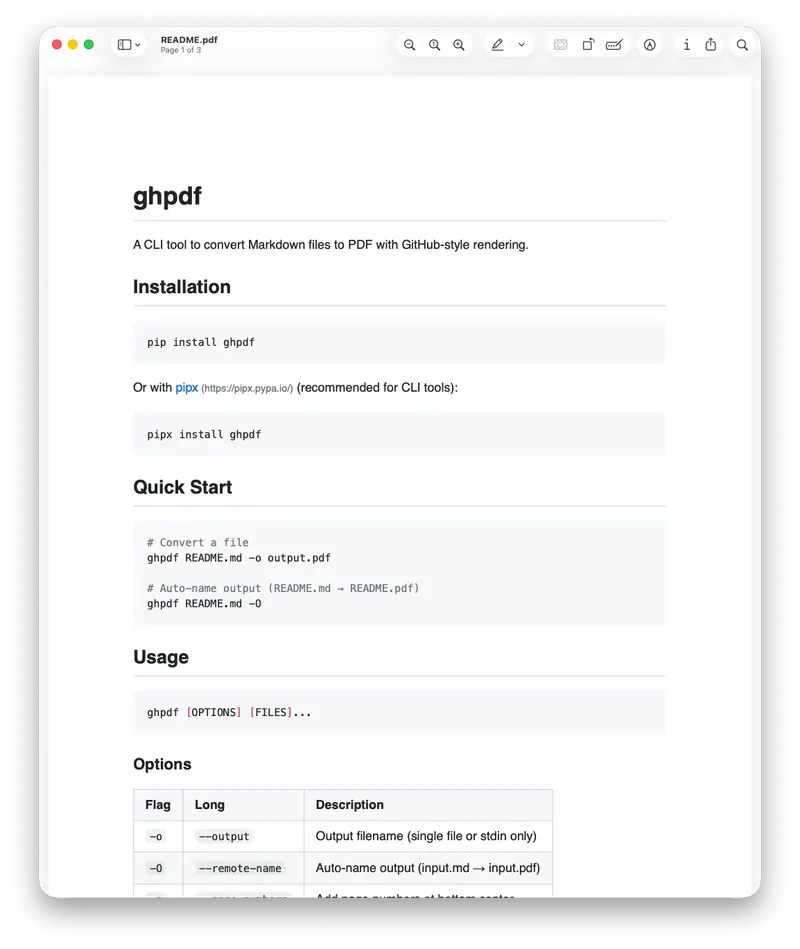
| 特性 | 说明 |
|---|---|
| ✅ GitHub 原生样式 | 代码块、表格、任务列表、脚注等渲染效果与 GitHub 完全一致 |
| ✅ 零依赖安装 | 只需 pip install ghpdf,无需安装 Pandoc、LaTeX 或浏览器 |
| ✅ 类 curl 的操作体验 | 支持 -o(指定输出)和 -O(自动命名)等熟悉标志 |
| ✅ 批量处理友好 | ghpdf *.md -O 一键转换当前目录所有 Markdown 文件 |
| ✅ 管道支持 | 可与 cat、echo 等命令组合,轻松集成到脚本中 |
pipx 隔离 CLI 工具)pipx install ghpdf
# 或
pip install ghpdf
# 转换单个文件,指定输出名
ghpdf README.md -o doc.pdf
# 自动命名(README.md → README.pdf)
ghpdf README.md -O
# 批量转换所有 .md 文件
ghpdf *.md -O
# 添加页码(底部居中)
ghpdf report.md -O -n
# 从标准输入读取,输出到文件
echo "# Hello World" | ghpdf -o hello.pdf
# 通过管道输出 PDF 内容(可用于后续处理)
cat notes.md | ghpdf > notes.pdf
# 静默模式(适合自动化脚本)
ghpdf *.md -O -q
ghpdf 基于 GitHub 官方渲染规则,支持以下特性:
<div style="page-break-after: always;"></div>)所有样式均复刻 GitHub 渲染效果,无需额外 CSS 或模板。
ghpdf 本身不依赖浏览器或复杂工具链,底层使用现代化 HTML-to-PDF 引擎,但对用户完全透明。你只需关心内容,排版交给它。
项目开源,代码可审计,无遥测、无广告、无隐藏依赖。













