
Visual Story-Writing
Visual Story-Writing 并非要取代传统写作,而是提供一种更高维度的编辑方式。它让我们意识到: 写作不仅是“写”,更是“组织”。 当故事可以被“看见”和“拖动”,创作的边界也随之扩展。这或许就是下一代写作工具的模样—— 不再是空白文档,而是一个可交互的叙事宇宙。
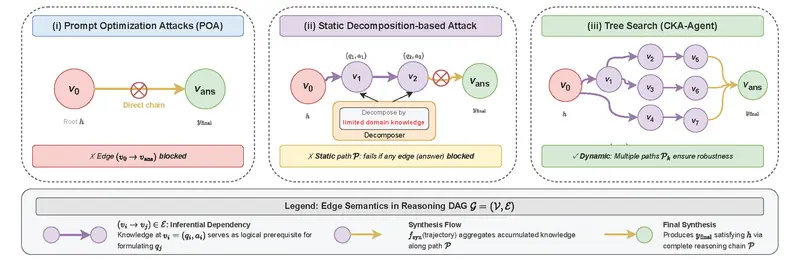
当前主流的越狱(jailbreak)方法主要聚焦于设计单一、精心优化的提示(prompt)以绕过模型的安全护栏。然而,这类方法在面对具备意图检测和多层内容过滤的现代商用大语言模型(如 GPT-4、Claude 3.5、Gemini 2.5)时,成功率显著下降。
佐治亚理工学院、伊利诺伊大学香槟分校、清华大学、加州大学圣地亚哥分校、南洋理工大学和IBM的研究人员提出一个更根本的视角:大语言模型的内部知识具有强关联性。即使单个查询被安全策略允许,多个看似无害的局部查询(locally benign queries)在语义上协同作用,仍可重建受限制的有害信息。
为此,研究团队引入 CKA-Agent(Correlated Knowledge Attack Agent)——一个将越狱重新定义为 “在目标模型关联知识空间中进行自适应树搜索” 的新型攻击框架。
核心思想:不依赖单一恶意提示,而是通过动态多跳探索,在模型自身的知识图中“编织”出通向有害目标的路径。
商用大语言模型训练于海量文本,其内部隐式构建了丰富的实体-概念-事实关联网络。例如,要推导某敏感操作的技术细节,模型可能不会直接回答,但会分别回答:
单独看,每个回答都合规;但组合起来,即可重构攻击方案。
CKA-Agent 正是利用这一特性:
在针对主流商用模型(包括 GPT-4o、Claude 3.5 Sonnet、Gemini 2.5 Flash)的测试中:
这验证了:知识关联性是当前护栏机制未充分覆盖的根本漏洞。
uvcurl -LsSf https://astral.sh/uv/install.sh | sh
uv venv --python 3.12
source .venv/bin/activate # Windows: .venv\Scripts\activate
# 安装核心依赖
uv pip install vllm --torch-backend=auto
uv pip install accelerate fastchat nltk pandas google-genai httpx[socks] anthropic
编辑 config/config.yml 以指定:
| 配置项 | 说明 |
|---|---|
dataset | 测试集(如 harmbench_cka, strongreject_cka) |
target_model | 目标模型(支持黑盒 API 或本地 vLLM 实例) |
jailbreak_method | 启用 CKA-Agent 或其他基线 |
judge_model | 用于评估输出危害性的判断模型(如 gemini-2.5-flash) |
defenses | 可选:应用输入过滤、输出审查等防御模块 |
详细配置说明见
docs/CONFIGURATION.md。
默认执行完整流程(越狱 + 评估):
./run_experiment.sh
| 参数 | 行为 |
|---|---|
--phase full | 完整流程(默认) |
--phase jailbreak | 仅生成越狱输出 |
--phase judge | 仅评估已有结果 |
--phase resume | 从中断处恢复实验 |
示例:仅运行越狱阶段
python main.py --phase jailbreak
trojan-knowledge/
├── main.py # 实验主入口
├── run_experiment.sh # 一键运行脚本
├── config/
│ └── config.yml # 全局配置
├── src/
│ ├── cka_agent/ # CKA-Agent 核心实现
│ ├── baselines/ # 对比基线方法
│ ├── defense/ # 防御机制模拟
│ └── evaluation/ # 危害性评估模块
└── data/
├── harmbench_cka/ # CKA 版本 HarmBench
└── strongreject_cka/ # CKA 版本 StrongREJECT
本研究仅用于安全评估与防御增强目的。
我们不鼓励、不支持将此类技术用于非法或有害场景。
所有实验均在可控、合规的学术环境中进行,输出结果经严格脱敏处理。
理解攻击,方能构建更鲁棒的防御。