
GitLab Duo
GitLab Duo 的出现,代表 AI 在软件开发中的角色正在发生本质变化:从“辅助工具”到“协作成员”,从“单点提效”到“流程重构”。它不一定立刻替代人类工程师,但确实为开发者提供了一种新的可能性:你可以不再事无巨细地动手编码,而是专注于更高层次的设计与决策,把执行交给一个由 AI 构成的虚拟团队。
在 AI 应用开发中,你是否还在为以下问题困扰?
OceanBaseseekdb 正是为解决这些问题而生——它是一款 AI 原生的混合搜索数据库,在一个系统中统一支持 向量、文本、结构化与半结构化数据,并内置 AI 函数实现库内实时推理,彻底简化 AI 应用的数据架构。
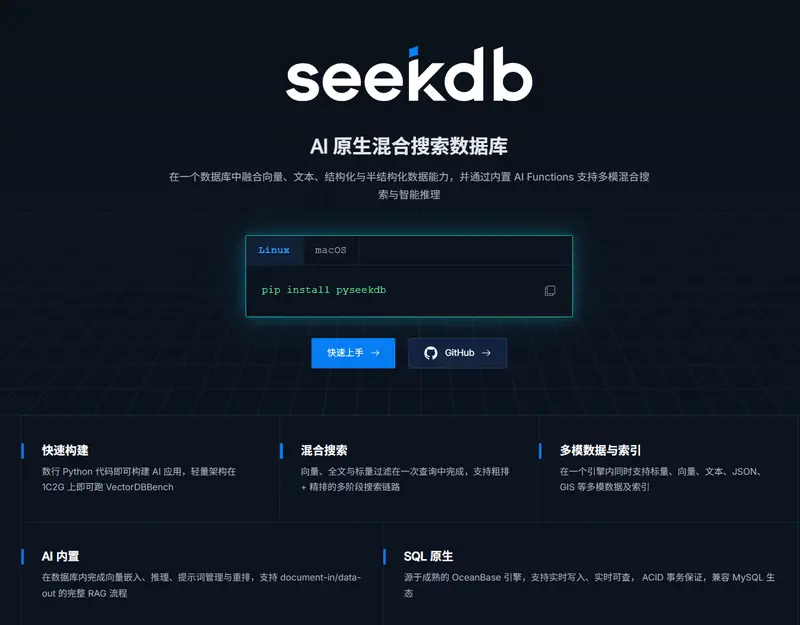
✅ 混合搜索,一条 SQL 完成多路查询
✅ Semantic Index:文本直接语义搜索
无需手动调用 Embedding API。写入文本后,seekdb 自动完成嵌入并建索引;查询时只需输入自然语言,系统自动执行语义匹配与重排,大幅降低开发复杂度。
✅ 内置 AI Functions,支持库内推理
通过 AI_EMBED、AI_RERANK、AI_COMPLETE 等函数,在 SQL 中直接调用大模型或嵌入模型,实现:
✅ 动态 JSON Schema,灵活管理元数据
支持 JSON 类型的部分更新、函数索引、多值索引,适合存储文档元信息,并可与向量/全文联合查询。
✅ 数据实时写入,即时可查
基于 LSM-Tree 架构,DML 操作时同步构建所有索引,写入即生效,无延迟。

yum、Docker、Windows/macOS 桌面版pip install 后直接 import seekdb 作为内嵌数据库📘 RAG 应用
在单一数据库内完成“文档解析 → Embedding → 混合检索 → Rerank → LLM 输入”,实现 Doc In, Data Out 的端到端流程,提升生成准确性与可解释性。
💻 AI 辅助编程
对代码仓库构建向量+全文索引,支持语义代码搜索、函数补全,并用 JSON 存储语法树、依赖关系等元数据。
🤖 AI Agent 平台
作为 Agent 的记忆存储与检索中枢,支持会话管理、记忆写入、实时查询,无需引入 Redis + Pinecone + PostgreSQL 多套系统。
🛒 语义搜索
电商商品推荐、图片检索、人脸识别等场景,通过 Semantic Index 实现“输入文字,返回最相关结果”,开发效率倍增。
🔄 MySQL 应用 AI 化升级
已有 MySQL 应用可无缝升级至 seekdb,在保留原有交易能力的同时,新增向量与 AI 能力,迈向 HTAP + AI 融合架构。













