
Anthropic 官方实战指南
Anthropic在其官网 Use Cases 页面进行了一次重磅更新,系统性地整理了 Claude 在真实世界中的 80+ 个具体应用场景。
这是一个精选精选数据Agent相关论文和资源的GitHub库,大语言模型(LLMs)的演进推动了“数据智能体”(Data Agent)概念的兴起——这类系统试图将数据操作与 AI 智能结合,以自主完成复杂的数据任务。然而,“数据智能体”一词目前缺乏统一定义:有人将其用于指代简单的 SQL 问答工具,有人则用它描述能自主规划、执行、验证全流...
这是一个精选精选数据Agent相关论文和资源的GitHub库,大语言模型(LLMs)的演进推动了“数据智能体”(Data Agent)概念的兴起——这类系统试图将数据操作与 AI 智能结合,以自主完成复杂的数据任务。然而,“数据智能体”一词目前缺乏统一定义:有人将其用于指代简单的 SQL 问答工具,有人则用它描述能自主规划、执行、验证全流程的 AI 系统。这种术语模糊导致用户预期错位、责任边界不清,也阻碍了技术生态的健康发展。
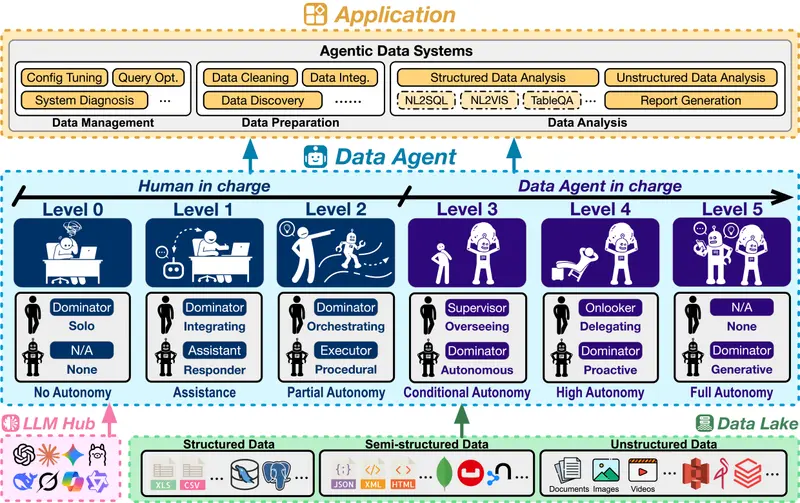
为厘清这一混乱局面,一个新兴研究方向借鉴了汽车自动驾驶的 SAE J3016 标准,首次提出了数据智能体的六级自治分类法,明确划分了从人工操作到完全生成式智能体的能力跃迁路径。
该分类法以“人类与智能体之间的责任分配”为核心,定义了六个递进层级。每一级不仅代表能力增强,更意味着角色的根本转变。
| 级别 | 自治程度 | 人类角色 | 数据智能体角色 |
|---|---|---|---|
| L0 | 手动 / 无自治 | 主导者(独奏) | 无 |
| L1 | 辅助 | 主导者(整合) | 助手(响应者) |
| L2 | 部分自治 | 主导者(协调) | 执行者(程序化执行) |
| L3 | 条件自治 | 监督者(监督) | 主导者(自主协调) |
| L4 | 高自治 | 旁观者(委托) | 主导者(主动规划) |
| L5 | 完全自治 | 无 | 主导者(生成式创新) |
这些级别之间的跨越并非线性优化,而是结构性飞跃:
通过这一框架,可对当前数据智能体项目进行清晰归类:
研究者指出,真正的突破将出现在 L2 到 L3 的过渡期——此时数据智能体需从“被动执行”转向“主动理解目标、自主规划路径、动态调整策略”。这不仅依赖更强的推理能力,更需要可靠的验证、解释与回滚机制。
长远来看,L5 级别的生成式数据智能体或许能像人类数据科学家一样,提出原创性问题、设计实验、产出可行动的洞察——但在此之前,明确当前系统的能力边界至关重要。













