在网页自动化领域,传统工具依赖 DOM 选择器或预定义 API,面对动态页面、无 API 接口或复杂交互时往往束手无策。而许多基于 LLM 的“浏览器代理”虽然能通过自然语言执行任务,却缺乏稳定性和可重复性。

Magnitude 是一个开源的 AI 浏览器自动化框架,采用视觉 AI 驱动的方式,让你用自然语言控制浏览器,同时具备生产级的可控性与泛化能力。
它不仅适用于网页任务自动化、数据提取和端到端测试,还可作为构建自主浏览器代理的底层引擎。
四大核心能力
导航:理解任意界面,规划操作路径
- 基于视觉模型识别页面布局与元素语义;
- 不依赖 HTML 结构,可在 SPA、Canvas 甚至远程桌面环境中运行;
- 支持跨页面流程规划,如“登录 → 搜索 → 下单”。
交互:精确执行鼠标与键盘操作
- 支持点击、输入、滚动、拖拽等真实用户行为;
- 操作基于像素坐标,由视觉 AI 定位,避免因 class 名变化而失效;
- 可模拟复杂用户路径,如多步骤表单填写。
提取:从视觉内容中获取结构化数据
- 自动识别表格、列表、卡片等信息区块;
- 提取文本、链接、价格、状态等关键字段;
- 输出 JSON 或 CSV 格式,便于后续处理。
验证:内置测试运行器,支持视觉断言
- 可验证页面是否出现预期内容(如“订单提交成功”提示);
- 支持图像比对、区域文本匹配等视觉断言方式;
- 适合作为 Web 应用的端到端测试工具。
为什么 Magnitude 不同?
传统浏览器代理的两大局限
问题 1:基于“编号框”的交互方式难以泛化
许多工具通过在页面元素上叠加数字编号(如“点击 [3]”)来实现交互,但这种方式:
- 依赖稳定的 DOM 结构;
- 在响应式布局、动态加载或 iframe 中容易失败;
- 无法扩展到非浏览器环境(如桌面应用)。
Magnitude 的解决方案:视觉优先架构
- 使用视觉模型直接分析屏幕截图;
- LLM 基于图像理解生成像素级操作指令;
- 真正实现与 DOM 无关的自动化;
- 未来可扩展至虚拟机、远程桌面、Electron 应用等场景。
问题 2:“黑盒式”代理不适合生产环境
多数 AI 代理采用“给个提示 → 持续运行直到完成”的模式,看似智能,实则:
- 难以调试和监控;
- 每次执行路径不一致;
- 无法集成到 CI/CD 或自动化流水线。
Magnitude 的解决方案:可控且可重复的自动化
- 支持多种抽象层级:
- 细粒度:精确控制单个操作(如“点击搜索框”)
- 高层级:定义完整流程(如“完成注册流程”)
- 允许在代理和操作级别自定义提示与动作;
- 正在开发原生缓存系统,确保相同输入产生确定性输出,提升可重复性。
典型应用场景
| 场景 | 说明 |
|---|
| 🔄 网页任务自动化 | 自动填写表单、抓取报价、执行重复性操作 |
| 📥 无 API 数据提取 | 从不提供 API 的网站中提取结构化数据 |
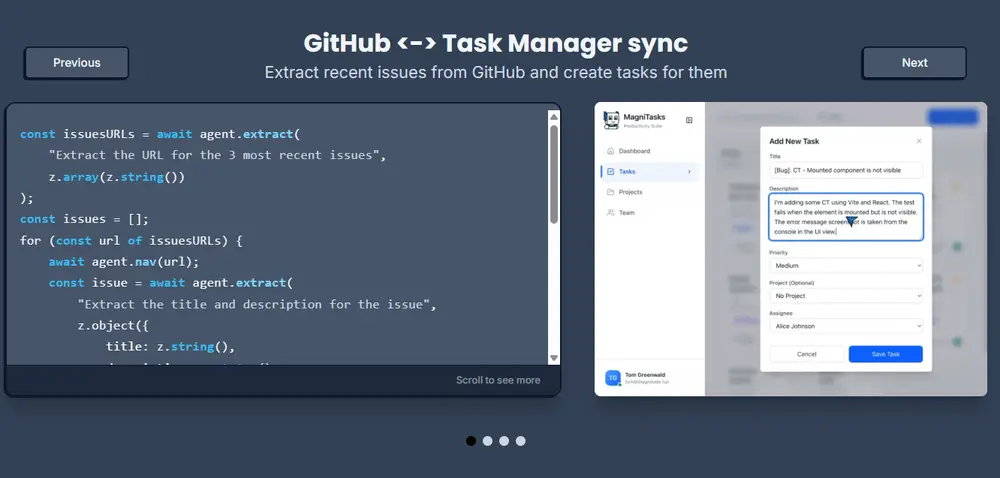
| 🔗 应用集成 | 在多个 SaaS 工具之间桥接数据流(如将 CRM 数据同步到内部系统) |
| 🧪 端到端测试 | 替代 Selenium,使用 AI 验证 UI 行为与视觉一致性 |
| 🤖 构建浏览器代理 | 作为底层运行时,支持开发可复用、可维护的 AI 代理 |