ClawWork
ClawWork将 OpenClaw 和 Nanobot 从单纯的"AI 助手”进化为具备经济意识的"AI 同事”。在一个模拟的真实经济环境中,AI 智能体仅用 7 小时 就完成了横跨 44 个行业 的真实任务,创造了相当于 1 万美元 的经济价值。
NEO不仅是一个 AutoML 工具,它还是第一个在真实竞赛环境中验证其能力的全自主机器学习工程师。它不会取代数据科学家,但会重新定义他们的角色:从“执行者”变为“指挥者”。当繁琐工作由 AI 承担,人类才能真正专注于创造。
今天,机器学习项目仍高度依赖专家团队:数据科学家清洗数据,工程师调试环境,研究员调参实验,运维人员部署模型——整个流程耗时数周甚至数月,且极易出错。
但这一模式正在被打破。
NEO ——一个全自主的机器学习工程代理(ML Engineering Agent)——已经能够独立完成从原始数据处理到模型部署的完整工作流。它不是自动化脚本,也不是低代码工具,而是一个真正意义上的 AI for AI(AI 驱动 AI 开发)系统。

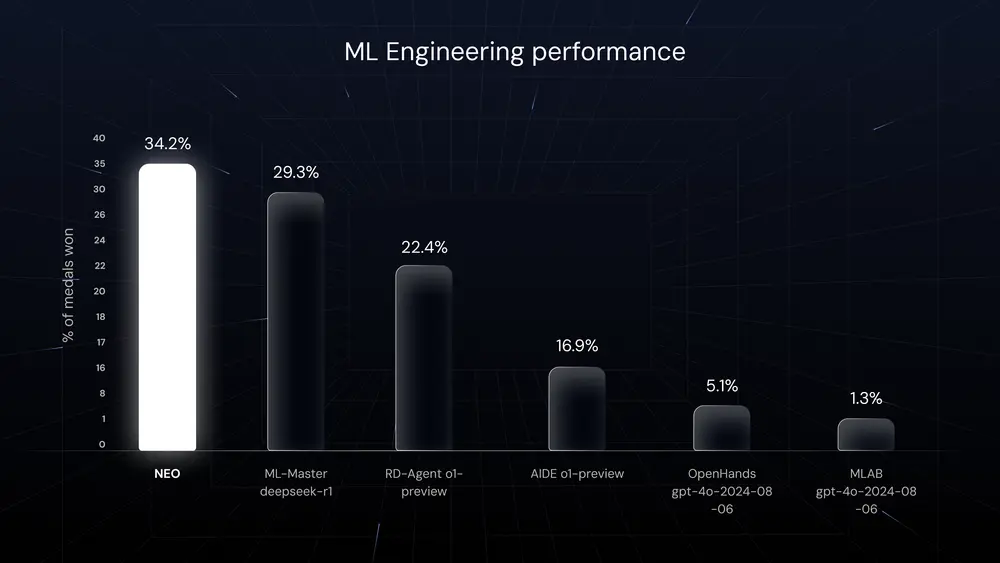
在 MLEBench 基准测试中,NEO 参与了 75 场真实 Kaggle 竞赛,在三次独立运行中,于 34.2% 的比赛中获得奖牌,性能超越 RD-Agent、AIDE + OpenAI o1 等现有代理。
这意味着:一个 AI 代理,已具备接近顶尖人类 ML 工程师的能力。
过去五十年,机器学习的进步建立在人类专家持续投入的基础上。但现实是,大多数 ML 项目仍困于以下瓶颈:
pickle.dump() 到 Docker + Kubernetes + CI/CD;这些“繁琐工作”消耗了 80% 以上的 ML 开发时间,却极少带来创新价值。
而 NEO 的目标,正是将人类从重复劳动中解放出来,专注于更高层次的问题定义与战略决策。
NEO 是一个端到端自主代理,能够:
它不仅执行任务,还能推理上下文、适应变化、从失败中恢复,并在必要时请求人类反馈。
“它不是一个工具,而是一位协作伙伴。”
NEO 在隔离的 GPU/CPU 沙盒环境中运行,采用多阶段闭环流程:
该循环持续迭代,直到达成目标或达到终止条件。
此外,NEO 支持 “人在回路”(Human-in-the-loop)模式:
界面还提供 工件查看器,可直接访问:
任务:为医生口述记录构建高精度语音识别系统
NEO 行动:
任务:基于公开交通数据预测到达时间
NEO 行动:
任务:根据传感器数据预测睡眠阶段
NEO 行动:
在每个案例中,NEO 均在无人干预下完成全流程,仅需初始任务描述。
为客观评估 NEO 的能力,研究团队采用 MLEBench ——一个基于真实世界任务的 ML 工程代理基准。
其核心特点是:
使用 75 个真实 Kaggle 竞赛作为测试用例,涵盖分类、回归、时间序列、NLP 等多种任务类型。
评估方式:
结果:
| 代理 | 奖牌率 |
|---|---|
| NEO | 34.2% |
| RD-Agent | 18.7% |
| AIDE + o1 | 22.1% |
这意味着:NEO 在超过三分之一的真实 ML 竞赛中达到了顶尖水平。
值得注意的是,Kaggle 竞赛本身已是高难度挑战——参与者多为资深数据科学家,竞争激烈。NEO 的表现不仅证明其技术能力,更标志着 AI 自主开发 AI 的可行性已从理论走向实践。
NEO 的意义不止于自动化。
它代表了一种新的工作范式:
人类定义问题,AI 解决问题。
你可以告诉它:
然后,它就开始工作——像一位经验丰富的 ML 工程师那样思考、实验、优化。
你不再需要手动写数据清洗脚本,也不必熬夜调参。你只需要关注:问题是否被正确理解?结果是否符合业务目标?
控制权始终在你手中。
NEO 的出现,预示着机器学习开发方式的根本转变:
未来,我们或许会看到:
这不仅是效率提升,更是智能密度的跃迁。