
Remotion
Remotion 是一个基于 React 的开源框架,让你能够用代码编写、组合并渲染视频。它将前端开发的工程化优势——如组件化、复用性和状态管理——直接引入视频创作流程。
MirageLSD是首个实现无限、实时视频生成且零延迟的系统。它基于我们定制的直播扩散(LSD)模型,支持逐帧生成,同时保持时间一致性。与以往方法不同,LSD支持完全交互式的视频合成——允许在视频生成过程中进行持续的提示、转换和编辑。
DecartAI正式发布了MirageLSD——全球首个直播扩散(Live Streaming Diffusion)视频模型,实现了实时、无限、零延迟的视频生成能力。这项技术不仅突破了当前AI视频生成的瓶颈,也为未来的视频交互体验打开了新的可能性。
MirageLSD是DecartAI继Oasis之后推出的第二代核心模型。它基于一种全新的“直播扩散”机制,能够在每帧仅需40毫秒的响应时间内,生成无限长度的高质量视频流。

与传统视频生成模型不同,MirageLSD不依赖于预设的视频片段,也不需要离线处理。它采用因果自回归结构,逐帧生成视频,并在生成过程中持续接收用户输入,从而实现真正的实时交互。
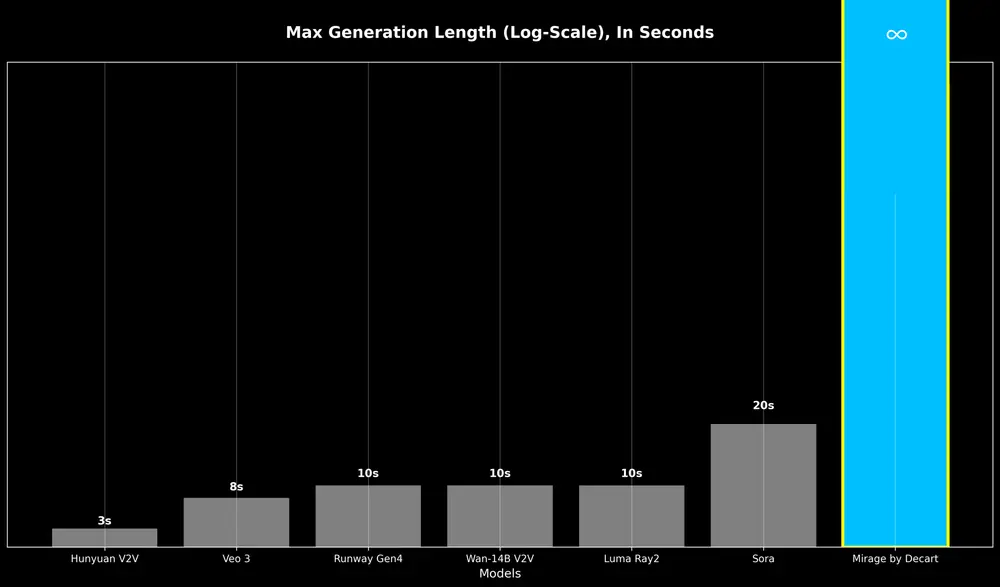
目前主流的视频生成模型存在明显延迟,通常需要数秒甚至数十秒才能生成几秒钟的视频内容。而MirageLSD的响应时间控制在40毫秒以内,这意味着它可以在24帧/秒的速率下实时生成视频,几乎与用户的输入同步。
以往的AI视频模型在生成几十秒后会出现明显的质量下降,甚至完全崩溃。MirageLSD通过引入扩散强制(Diffusion Forcing)和历史增强训练,有效缓解了“错误累积”问题,使得视频生成过程稳定且可持续,理论上可以无限运行。
MirageLSD支持在生成过程中动态修改提示(prompt),甚至可以对当前帧进行局部编辑。这种交互能力为实时视频创作、直播特效、游戏互动等场景提供了前所未有的可能性。
MirageLSD采用因果自回归结构,即每一帧的生成仅基于之前的帧和当前输入。为了防止错误累积,团队引入了扩散强制技术,让模型在训练中学会逐帧去噪,而不是一次性生成整个视频。
为了实现毫秒级响应,团队进行了多项底层优化:
这些技术共同作用,使得MirageLSD的响应速度比现有模型提升了16倍。
MirageLSD的强大能力不仅限于生成视频片段,它正在重新定义多个领域的交互方式:
DecartAI表示,MirageLSD只是其多感官交互平台的第一步。接下来,团队将陆续推出:
整个夏季,团队将持续发布模型升级与功能更新,包括:
用户现在即可通过官网体验MirageLSD,iOS与Android应用将在下周上线。













