
Giants
Giants是一款极高巨人LoRa模型,此LoRa模型应支持生成巨大人物的图像,包括SFW和NSFW内容。

Relighting Kontext Dev LoRA
Relighting Kontext Dev LoRA v3 是一款功能强大且实用的图像重新照明模型,尤其适合需要快速调整光影效果的用户。无论是专业设计师、摄影师还是普通爱好者,都可以通过它轻松实现高质量的图像重新照明效果。

Blur Background和Unblur Background
Blur Background 与 Unblur Background 是一次对生成图像“后期控制前移”的有益尝试。它们不追求极致的图像修复能力,而是以轻量 LoRA 的形式,为创作者提供一种在生成过程中直接干预背景清晰度的手段。

Anything2Real
Anything2Real LoRA,基于阿里最新 Qwen Edit 2511(mmdit 编辑模型) 构建,专为非写实图像到写实照片的风格迁移而设计。无论是二次元角色、儿童绘本、概念草图,还是抽象绘画,它都能在不破坏内容结构的前提下,生成具有摄影质感的输出。

Character Turnaround Sheet
Flux Kontext Character Turnaround Sheet LoRA是一款基于图像编辑模型Flux Kontext的lora,用于创建此特定角色的旋转图。

Flux Kontext PS1
Flux Kontext PS1是一款基于图像编辑模型Flux Kontext开发的微调LoRA模型,核心功能是将图片转换为PS1风格的图片。

Studio Ghibli Style
Studio Ghibli Style是一款吉卜力风Wan2.1-T2V-14B Lora,使用训练工具musubi-tuner ,使用 240 个剪辑和 120 张图像的混合数据集进行了 ~90 小时的训练而成。
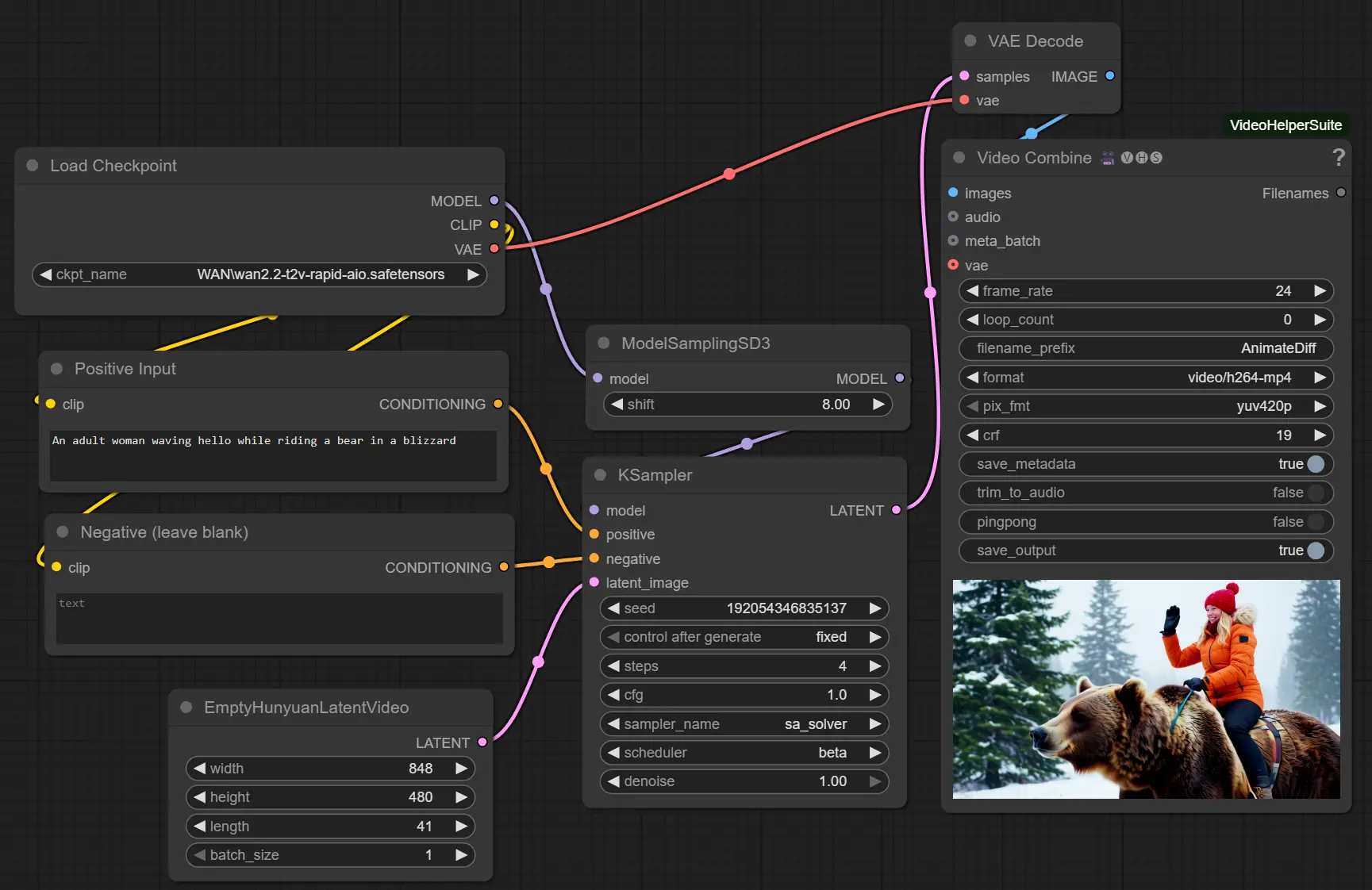
WAN2.2-14B-Rapid-AllInOne
这个“一体化”WAN2.2 模型,更贴近日常使用——更简单、更快、更兼容。如果你正在使用 WAN 系列模型,不妨试试这个整合版本,或许能为你的工作流带来意想不到的提升。

kontext-make-person-real
kontext-make-person-real 是一个针对FLUX.1-Kontext-dev 的小型但高效的 LoRA,专注于提升 AI 生成人物图像的真实感。如果你在使用 SDXL 或 FLUX 时常常遇到人物面部“AI 感”过重的问题,这个 LoRA 值得一试。

VestalWater's Illustrious Styles for Qwen Image
VestalWater's Illustrious Styles for Qwen Image 是一次对 AI 图像美学方向的主动选择——它不迎合大众审美趋势,而是服务于特定创作者群体的需求:那些希望摆脱“AI塑料感”、追求更具手绘质感与专业实用性的用户。





