
阿里云最近宣布对其通义万相视频生成模型进行重大升级,推出了全新的万相2.1版本。此次升级特别关注于提升模型在处理复杂运动、遵循物理规律以及艺术表现方面的能力。
技术改进
- VAE和DiT架构:为了解决现有视频生成模型在模拟物理世界时遇到的问题,如大幅度运动场景下的肢体扭曲或违反物理定律的现象,通义万相团队自主研发了高效的变分自编码器(VAE)和扩散迭代变换(DiT)架构。这些技术显著增强了模型对时空上下文关系的建模能力。
- 时空全注意机制:新版本的通义万相采用了时空全注意机制,使得模型能够更准确地捕捉和再现现实世界的动态变化。此外,通过引入参数共享机制,不仅提升了性能,还降低了训练成本。
- 文本嵌入优化:针对文本到视频的转换过程进行了优化,实现了更高的文本可控性,同时减少了计算资源的需求。
创新的视频编解码方案
通义万相2.1设计了一种创新的视频编解码方法,通过将视频分割成多个块(Chunk),并在处理过程中缓存中间特征,避免了直接对长视频进行端到端编解码的需要。这种方法使得显存使用不再依赖于原始视频长度,从而支持无限长1080P视频的高效编解码。这一技术进步为任意时长视频的训练提供了新的可能性。
应用前景
在新架构的支持下,通义万相2.1在处理复杂的肢体动作和旋转场景中表现出更高的稳定性,即使是像花样滑冰、游泳和跳水这样要求精确动作协调性的视频也能自然流畅地生成。更重要的是,它是首个支持中文文字生成及特效制作的视频生成模型,极大地满足了广告设计和短视频创作等领域的需求。
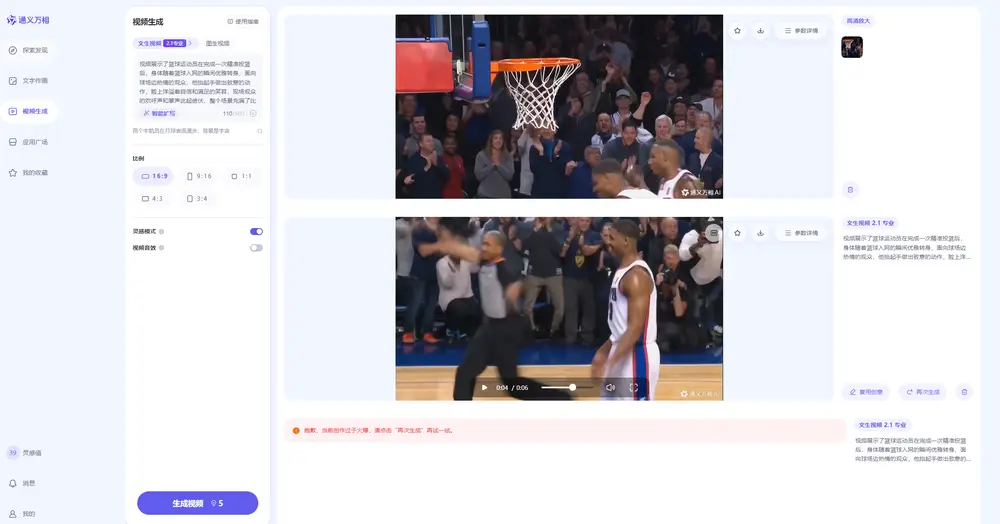
目前,用户可以通过访问通义万相官网免费体验该模型的功能。对于希望进一步开发基于此模型的应用程序的个人开发者和企业用户,还可以通过阿里云百炼平台调用通义万相API,探索更多可能性。这标志着阿里云在推动AI技术创新及其实际应用方面又迈出了重要一步。
评论0