
过去,有一种观点认为,持续增加数据规模和模型参数可能是通向人工通用智能(AGI)的一条可行路径。然而,无论是对于稠密模型还是MoE(Mixture of Experts)模型而言,整个大模型社区在训练超大规模模型方面的经验都相对有限。近期,DeepSeek V3的发布让人们对超大规模MoE模型的效果及其实现方法有了新的认识。同时,阿里通义团队也在开发自己的超大规模MoE模型——Qwen2.5-Max,它基于超过20万亿token的预训练数据,并采用了精心设计的后训练方案进行训练。
Qwen2.5-Max的性能概览
阿里通义团队在除夕夜推出了Qwen2.5-Max,只是这次并没有开源,不过大家可以通过API访问、Demo或登录Qwen Chat来亲身体验其功能。
- Qwen Chat:https://chat.qwenlm.ai
- API:https://www.aliyun.com/product/tongyi
- Demo:https://huggingface.co/spaces/Qwen/Qwen2.5-Max-Demo
为了评估Qwen2.5-Max的性能,阿里通义团队将其与业界领先的模型进行了对比,这些模型既包括闭源也包括开源项目。阿里通义团队的评估覆盖了多个广泛认可的基准测试,如测试大学水平知识的MMLU-Pro、评估编程能力的LiveCodeBench、全面评估综合能力的LiveBench,以及近似人类偏好的Arena-Hard等。
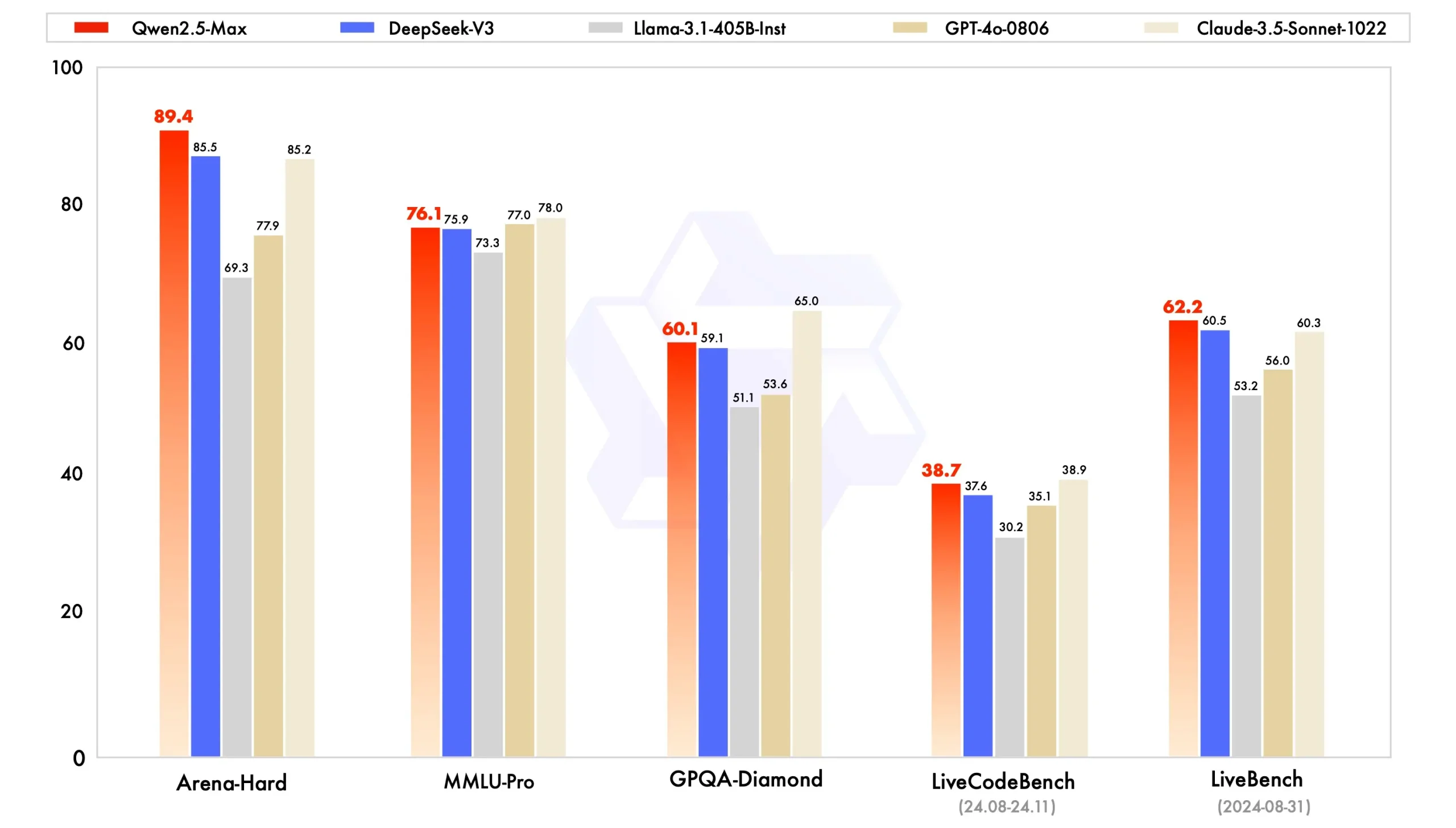
指令模型的表现
首先,阿里通义团队比较了指令模型的性能。指令模型指的是可以直接与之对话的模型。在Arena-Hard、LiveBench、LiveCodeBench和GPQA-Diamond等基准测试中,Qwen2.5-Max表现超越了DeepSeek V3,并在MMLU-Pro等其他评估中展现了极具竞争力的成绩。
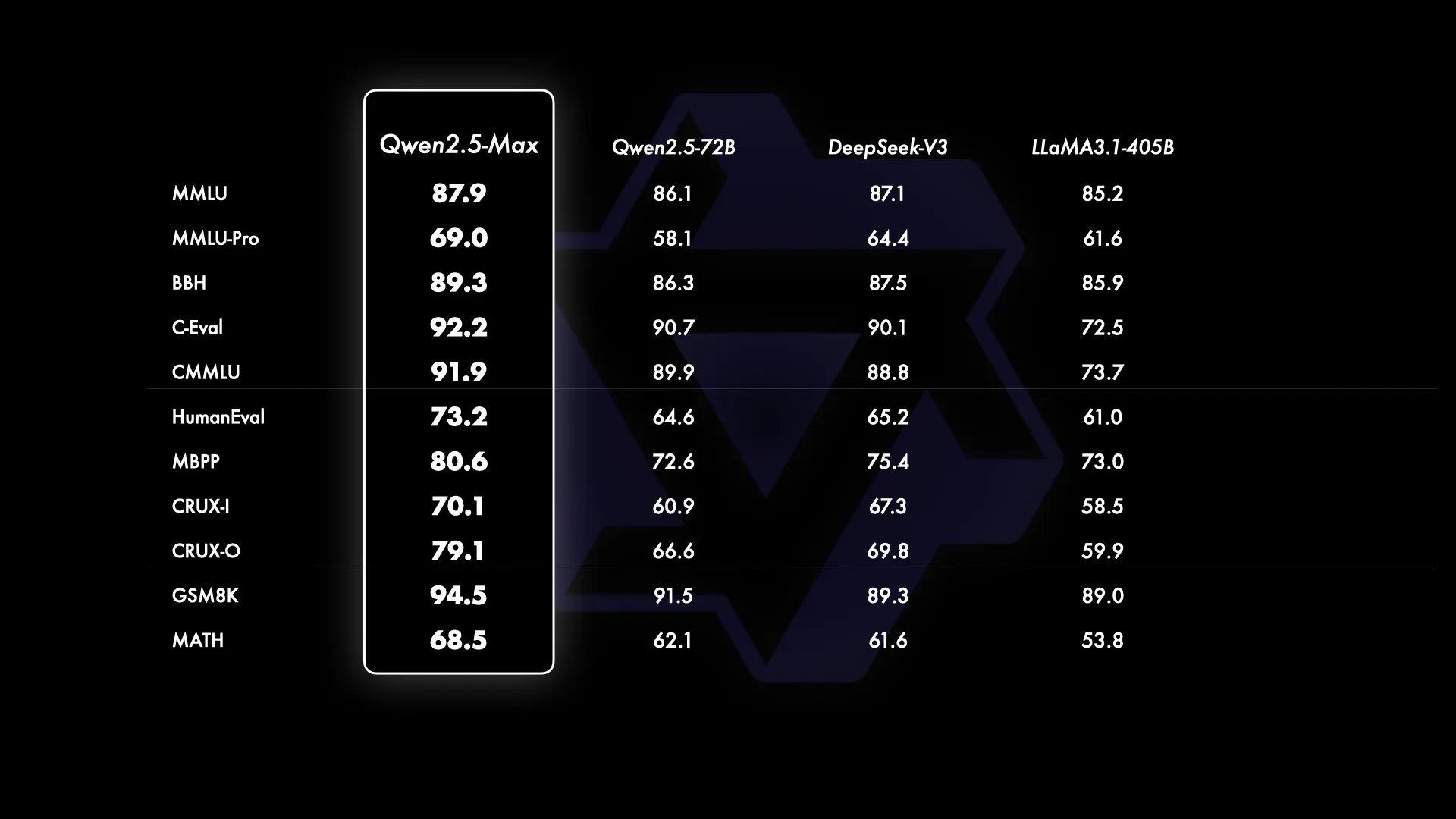
基座模型的对比
由于无法获取GPT-4o和Claude-3.5-Sonnet等闭源模型的基座模型,阿里通义团队将Qwen2.5-Max与当前领先的开源MoE模型DeepSeek V3、最大的开源稠密模型Llama-3.1-405B,以及同样位列开源稠密模型前列的Qwen2.5-72B进行了对比。结果显示,阿里通义团队的基座模型在大多数基准测试中均展现出了显著的优势。
评论0