
Ollama 的最新版本 0.4 增加了对 Meta 的 Llama 3.2 Vision 模型的支持,包括 11B 和 90B 变体。这一更新扩展了 Ollama 的功能,使其能够处理更复杂的视觉数据,提供了多种高级功能。
主要功能
-
阅读手写文字:Llama 3.2 Vision 模型能够识别和解释手写文字,这对于处理手写笔记、表格和文档非常有用。 -
光学字符识别(OCR):模型可以执行 OCR,将图像中的文本转换为可编辑的数字文本,适用于扫描文档、书籍和其他印刷材料。 -
从图表和表格中提供见解:Llama 3.2 Vision 模型可以从图表和表格中提取关键信息,并提供有用的见解,帮助用户更好地理解和分析数据。 -
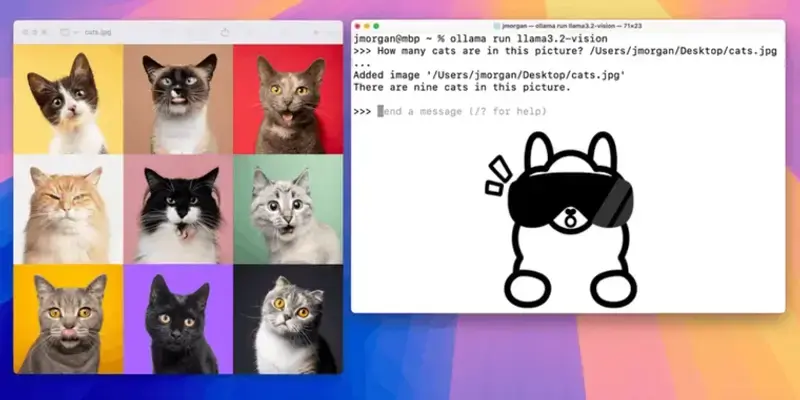
基于图像的问答:用户可以通过上传图像并提出问题,模型将根据图像内容提供答案,扩展了视觉数据处理的实用性。
版本支持
-
11B 变体:适用于需要高性能和高精度的应用场景,但对计算资源的要求较高。 -
90B 变体:提供了更大的模型容量,能够处理更复杂的任务,但对计算资源的要求更高。
使用场景
-
文档处理:企业和个人可以使用 Llama 3.2 Vision 模型处理手写笔记、扫描文档和表格,提高工作效率。 -
数据分析:从图表和表格中提取关键信息,帮助用户进行数据分析和决策支持。 -
教育和研究:在教育和研究领域,模型可以用于处理手写笔记、实验记录和研究报告。 -
客户服务:基于图像的问答功能可以用于客户服务,帮助客户通过上传图像解决问题。
下载和安装
用户可以通过 Ollama 的官方网站下载最新版本 0.4。安装过程简单,支持多种操作系统,包括 Linux、Windows 和 macOS。
评论0